In today’s cloud-first world, data sprawls across storage systems and platforms. Object stores like AWS S3 hold terabytes of rich, valuable information, but tapping into that value without moving the data has long been a challenge. But now thanks to Apache Iceberg and Snowflake’s support for external Iceberg tables, organizations can query data in place—keeping it in open formats while gaining Snowflake’s performance, governance, and security benefits. And with Coalesce, making it all work is no longer a heavy lift.
Unlocking full storage interoperability
Organizations today are creating and storing more data than ever before. Massive data sets allow them to build AI-driven features that customers now expect from modern business experiences: personalized recommendations, helpful chatbots, fraud detection, and more.
But with big data come big challenges. For one, data is often stored in one system or platform, but there are multiple tools within the organization that need access to that data. Being able to operate on a single copy of this data via multiple systems gives you a significant advantage–but this has historically been difficult to achieve.
Organizations normally have two options:
1) Writing and managing complicated data pipelines that span multiple systems, which are often brittle and difficult to maintain
2) Making an all-hands-on-deck effort to move data into a single warehousing solution like Snowflake and feeding that data when needed to other systems.
The first option can cause issues with maintainability and scalability, which makes taking action on your data much more difficult. The second option raises concerns about vendor lock, which can deter data teams who don’t want to be stuck with a solution that offers little to no interoperability.
Enter Apache Iceberg tables.
What is an Apache Iceberg table?
Apache Iceberg is an open table format designed to manage large-scale, analytics-optimized datasets. Think of it as a high-performance upgrade to traditional data lake tables.
Iceberg tables bring structure, consistency, and reliability to data stored in object storage by supporting features like ACID transactions, schema evolution, and time travel—capabilities once exclusive to data warehouses.
Snowflake and Iceberg tables
Iceberg unlocks new flexibility for hybrid and multi-cloud architectures. With Snowflake’s support for external Iceberg tables, organizations can query data stored in formats like Parquet directly in object storage (e.g., AWS S3, Azure Data Lake Storage, or Google Cloud Storage) without ingesting it into Snowflake. This allows you to keep data in an open format while benefiting from Snowflake’s powerful query engine, governance, and security capabilities.
Using Iceberg tables with Snowflake bridges the gap between open data lake architectures and enterprise-grade data platforms.
It enables data teams to:
- Avoid data duplication by querying external Iceberg tables in place
- Maintain interoperability across engines like Spark, Trino, and Snowflake
- Leverage Snowflake’s governance and access control on open-format data
- Enable schema flexibility and safe evolution without manual table rewrites
In short, Apache Iceberg empowers you to treat your object storage like a first-class citizen in Snowflake—without sacrificing performance, consistency, or openness.
Luckily, Snowflake customers have a reliable solution at their disposal—and it begins with the Snowflake Polaris Catalog.
What is the Polaris Catalog?
The Polaris Catalog is an open source catalog for Apache Iceberg, and a critical component for organizations with a multi-engine architecture. Polaris Catalog allows data teams to concurrently manage data pipelines through multiple systems.
This is possible because all read and write operations are routed through a catalog, allowing the same copy of data to be operated on, producing consistent results for all systems while also allowing each system to access the same data.
With the Snowflake Polaris catalog, you can now take advantage of Apache Iceberg table formats that exist in object storage like AWS S3, Google Cloud Storage, or Azure Blob Storage. Your data never has to be moved or copied into Snowflake and can instead be queried directly from the source through Snowflake’s query engine.
This resolves the concern around vendor lock-in because organizations can now query any Iceberg format table directly from the source system—while still being able to use Snowflake’s powerful features, regardless of where their data lives.
How to create an external volume and catalog
With Iceberg table support, Snowflake can query data from a multitude of systems including Amazon Web Services, Google Cloud, Microsoft Azure, Confluent, Dremio, and more. Additionally, Snowflake users can manage Iceberg tables within the Snowflake platform itself, exposing these tables to other systems that support Iceberg tables for added interoperability.
To start using Iceberg tables and take advantage of this interoperability, there are two primary requirements within Snowflake.
1) Create an external volume
Snowflake defines an external volume as:
“An external volume is a named, account-level Snowflake object that you use to connect Snowflake to your external cloud storage for Iceberg tables. An external volume stores an identity and access management (IAM) entity for your storage location. Snowflake uses the IAM entity to securely connect to your storage for accessing table data, Iceberg metadata, and manifest files that store the table schema, partitions, and other metadata.”
2) Create a catalog
Put simply, a catalog allows a compute engine to manage and load Iceberg tables. A catalog integration is necessary when your Iceberg tables are managed by systems other than Snowflake. When this happens, you will create a catalog that is an account-level object within Snowflake, and which stores information about how your metadata is organized.
Your external volume and catalog configuration will look something like this:
ALTER DATABASE iceberg_tutorial_db SET CATALOG = ‘SNOWFLAKE’;
ALTER DATABASE iceberg_tutorial_db SET EXTERNAL_VOLUME = ‘iceberg_external_volume’;
Once your external volume and catalog are configured, you can load and query data from your storage location directly within Snowflake. You now have the ability to query data across multiple systems within your organization without constraint.
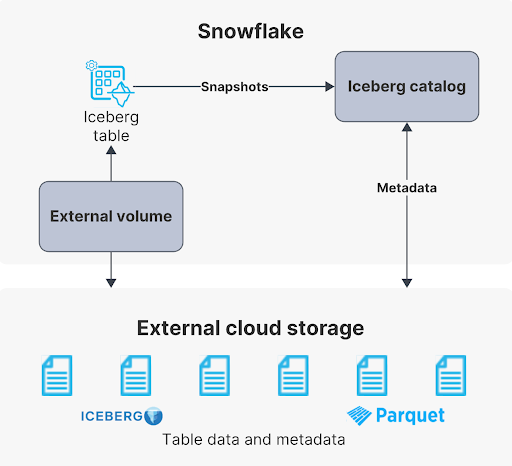
All this comes with an extra bonus: because the data you are querying is not stored in Snowflake, you are only charged for the compute used to query the data from the Iceberg tables—there is no storage cost associated with querying Iceberg tables in Snowflake.
Coalesce makes it easier
Setting up the ability to create and manage Iceberg tables does require some technical and architectural knowledge. But with Coalesce, customers can easily create and manage Iceberg tables directly in the Coalesce platform using Coalesce Marketplace.
By installing the Iceberg package, Coalesce customers can immediately take advantage of all the benefits discussed here.
Coalesce provides support for creating Iceberg tables at any of these three levels:
- Snowflake catalog
- AWS Glue catalog
- Object storage (AWS, Azure, and GCP)
This means that users can take advantage of each of the possible variations of Iceberg table support within Snowflake. As support for additional Iceberg catalogs becomes available, Coalesce will continue to implement that support into our Iceberg package.
With this functionality, Coalesce customers create Iceberg tables directly in Coalesce from a single interface—no need to understand the syntax, nor take multiple steps to complete the configuration. Because Coalesce makes the assumption that a catalog has already been created, you can pass it through as a catalog integration and begin creating and managing Iceberg tables in Coalesce.
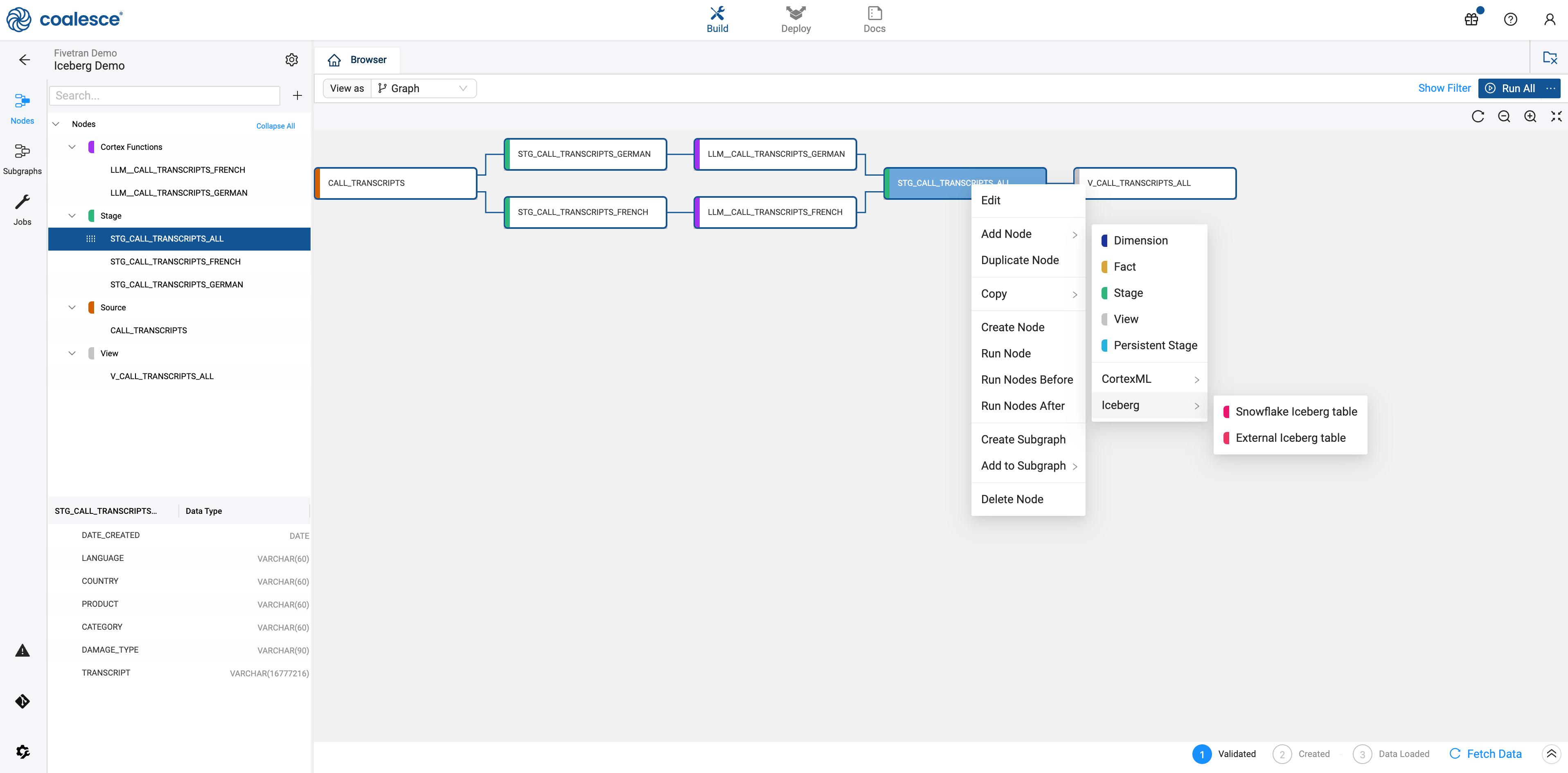
Opening the Node selector to add an Iceberg table to a pipeline in Coalesce.
What all of this means is that you can build your data pipelines in Coalesce using all the usual Snowflake functionality such as Dynamic Tables, Cortex Functions, and Tasks.
But now, thanks to Iceberg tables, you can also incorporate additional data sources and functionality to gain more data interoperability than has ever been available within the Snowflake ecosystem—and all without needing years of data engineering experience to accomplish it.
Watch the demo video below to learn how to take advantage of all of this functionality:

Try it for yourself
Data teams can try out our Iceberg Package which enables full use of Snowflake-supported Iceberg functionality. Additionally, our Streams and Tasks Package includes an Iceberg Table with Task Node which utilizes Snowflake-managed Iceberg Tables.
Want to learn more about Iceberg tables and Coalesce? Contact us to request a demo.
