Today, the average company collects data from more than 400 sources—including apps, websites, APIs, IoT devices, and more. This data helps business leaders steer organizational initiatives and inform everyday decisions. But all that raw data is not very useful for analysis. By itself, it won’t tell a story or answer questions raised by business domain teams. Raw data is often messy and inconsistent. It can be hard to analyze without data preparation. This is where data transformation is important.
Data transformation is an important part of ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform). These data management processes help move and prepare data for analyzing. They convert raw, unstructured data into structured, analytics-ready formats.
In the Modern Data Stack, data transformation is crucial. When data teams build data pipelines to analyze data in business intelligence (BI) tools, create data products, or create foundations for training AI/ML models, data transformation helps ensure that data is consistent, accurate, and ready for analysis.
In this article, we’ll cover the basics of data transformation, why it’s essential, and how it plays a vital role in data pipelines. We will also explore the benefits, techniques, and challenges organizations face when changing large, complex data sets.
What is data transformation?
Data transformation is the process of changing raw or unstructured data into a clean and organized format. This format is ready for analyzing, reporting, or further use downstream.
Data from different sources (e.g., databases, APIs, apps, and sensors) often comes in various formats and structures. Transformation changes this data by standardizing formats, cleaning errors, and making it available to other systems. This helps with analyzing, reporting, and processes such as machine learning.
Data transformation and the ETL/ELT process
ETL (Extract, Transform, Load)
ETL is a traditional way to process raw data into analytics-ready data sets.
- Extract: Data is pulled from various source systems (e.g., databases, APIs, flat files).
- Transform: The extracted data is cleaned, filtered, and formatted to meet the target schema and business needs. This includes removing duplicates, fixing missing values, and normalizing units.
- Load: The transformed data is loaded into a target data warehouse or database for analyzing.
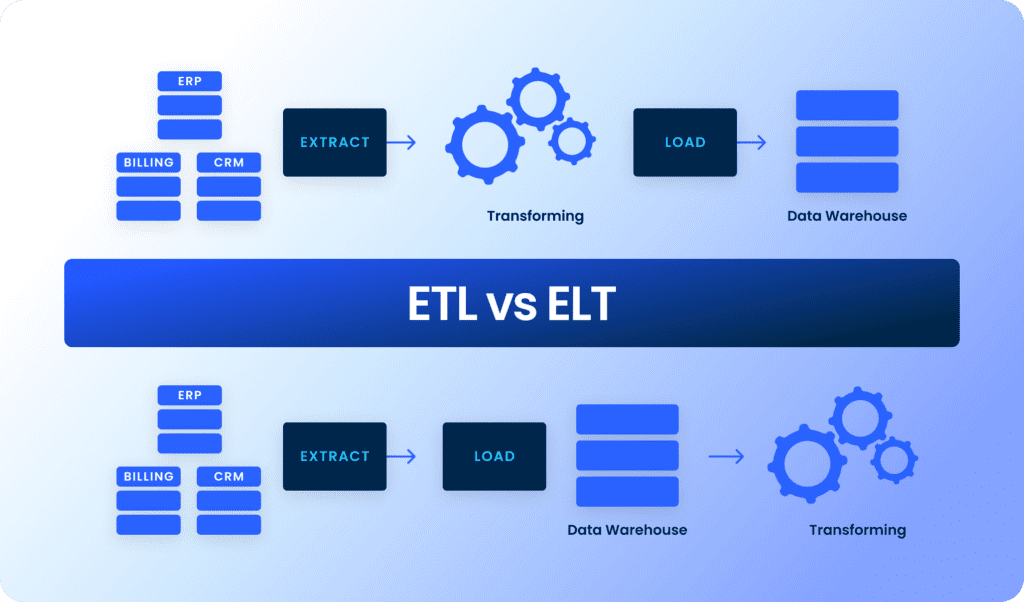
ELT (Extract, Load, Transform)
ELT is a newer, modern method for processing raw data for analysis.
- Extract: Data is pulled from various source systems.
- Load: Raw data is loaded directly into the target storage, such as a data warehouse or a data lake.
- Transform: Data transformation occurs after the data is loaded into the system. Data engineers perform this transformation on-demand, either within the data warehouse or via downstream tools.
As platforms such as Snowflake, Google BigQuery, and Microsoft Azure gain adoption, organizations are increasingly leveraging cloud-based solutions for data storage and analytics. These cloud platforms provide the storage and processing power to store and transform raw data. They also enable in-system data transformations. ELT, while not new, has become a popular alternative to ETL as cloud adoption grows.
Why is data transformation important?
Data transformation serves several critical functions, especially in today’s data ecosystem, where data comes from various systems. Here are some of the top reasons why it’s such a critical function in the analytics cycle:
Eliminates inconsistencies
Raw data often has issues like missing values, duplicates, and varying formats. For example, one data source might use a different date format, such as ‘MM-DD-YYYY’ instead of ‘YYYY-MM-DD.’ Another source might record product dimensions in inches, while another uses centimeters. Without transformation, this inconsistency would create chaos in your data analysis.
Improves data accuracy
Transformation helps eliminate errors and inconsistencies in datasets. This process includes deduplicating records, handling missing values, and identifying outliers. Clean, reliable data is crucial for making informed business decisions and deriving meaningful insights.
Ensures compatibility with analytics tools
Different data analysis and machine learning tools have specific data format requirements. For example, SQL tools work best with data stored in a table format. Other tools may need data changed into numbers or categories. Data transformation ensures that data is in the right shape for each of these tools.
Common types of data transformation
Several key techniques are used in the data transformation process. These are typically applied within a data pipeline to ensure that data is structured, cleaned, and prepared for further use:
Data cleansing
A foundational step in data transformation is cleansing, which involves eliminating duplicate records, addressing gaps in data, fixing inconsistencies, and standardizing formats. Without thorough cleansing, flawed data can lead to inaccurate analyses and unreliable business outcomes.
Data normalization
Normalization changes values to fit a certain range or scale. This is important when data comes from different sources with various units or ranges. For example, sales data in dollars may need to be adjusted. This helps account for changes in currency value between regions.
Data aggregation
Aggregation involves summarizing data, often by combining multiple data points into a single—more useful—summary. For instance, you might aggregate data from daily sales into weekly or monthly totals to simplify analyzing or reporting.
Data mapping
Data mapping makes sure that data fields in one data set match those in another. This can involve renaming columns, changing formats, or converting units to ensure they work together.
Data Enrichment
Sometimes, the raw data you collect isn’t enough on its own. Data enrichment improves current data by adding new information. This can include demographic data or third-party analytics. It helps enhance data to provide a better context for analysis.
Benefits of data transformation
The benefits of transforming your data before analyzing it extend beyond fixing data quality issues. Here are some of the key advantages:
Increased speed and efficiency
When data is automatically transformed and cleaned, it saves significant time for data teams. Data engineers don’t need to waste hours cleaning data sets by hand, and instead can focus on getting insights from the data. Automated transformation pipelines can handle large amounts of data much faster than doing it by hand.
Scalable data operations
As your organization grows, so does the volume and variety of data you handle. Data transformation makes sure that data from different sources can easily integrate into your data pipelines. This often includes data from business applications, websites, or platform APIs, for example.
Smoother integration and analysis
Data transformation makes integrating multiple data sets easier, enabling more comprehensive evaluations. By standardizing formats and units, you can turn raw data into one unified data set.
This creates a single “source of truth” for your business. Different teams in various departments can then use this data set. A unified data structure makes deriving meaningful insights that inform business decisions easier.
Improved data governance and compliance
Ensuring that data is cleaned, standardized, and transformed according to certain guidelines is critical to complying with industry and regional regulations such as GDPR or HIPAA. By implementing standardized transformation processes, businesses can ensure that they’re handling data securely and competently through access control and governance policies.
The role of data transformation and data modeling in data pipelines
Data transformation is critical to building robust data pipelines. These automated workflows move data from one system to another for storage and analysis. Data pipelines ensure that data flows seamlessly through ETL/ELT processes, allowing data teams to derive valuable insights from raw data sources.
While transformation focuses on cleaning and structuring data, data modeling helps define the relationships between different data points. Essentially, this creates a blueprint for how the data is organized, stored, and analyzed.
In data pipelines, data modeling and data transformation are interdependent. Data modeling provides the framework (e.g., star schema or Data Vault) that defines how data should be structured, while data transformation reshapes raw data to fit into that model. Together, they ensure that data flows smoothly from source to destination, ready for analysis and decision-making.
Suppose your data pipeline is built on a data warehouse with a star schema. In that case, the data model specifies how:
- Tables should be joined
- Facts and dimensions should be related
- Different data sets can be aggregated for efficient querying
The data transformation tool then maps, cleans, and transforms the raw data to fit the model.
Integrating data modeling into your transformation workflow helps ensure data pipelines are accurate, efficient, and manageable as volume and complexity grows. The combination of strong data transformation processes and well-designed data models is the foundation for building a scalable, reliable, and high-performance data pipeline.
Here’s how data transformation and data modeling work together to create efficient data pipelines:
Data integration
When data flows in from source systems—such as sales data from your e-commerce platform, customer data from your CRM, or marketing data from ad platforms—you need to transform and integrate these data sets into a cohesive structure. Data modeling is essential in this phase as it defines how the various data sets relate to one another, establishing clear schema and structure that help map data from one format to another.
Data transformation makes this possible by standardizing formats, converting units of measure, and aligning field names so you can effectively combine data from multiple sources. For instance, a customer ID in the customer relationship management (CRM) system might be labeled as cust_id, while in your marketing automation database, it might be customerID. During the transformation process, you can map these fields to a common name, making it easy to merge the two data sets.
In this case, data modeling can define relationships between customer records and sales transactions, ensuring that data from different systems aligns according to the specified schema. During the transformation process, the data is standardized, cleaned, and reshaped based on these relationships, creating a unified data structure for analysis downstream using a BI tool.
Reliable data workflows
Data pipelines require a structured flow of data from raw sources to final storage or analysis, and data modeling ensures that data is properly shaped before it moves through the pipeline. A strong data model defines the logical structure of your data, specifying how tables, fields, and entities relate to each other. This structure is crucial for making transformations both effective and efficient. Without it, data might get “lost in translation,” causing errors in later stages of the pipeline.
For example, suppose you’re transforming data into a star schema or Snowflake schema in a data warehouse. In that case, the underlying data model will define how facts (e.g., sales data) and dimensions (e.g., customer, time, product) relate. Transformation processes such as joining tables, aggregating values, and calculating metrics rely heavily on this model to ensure that relationships are maintained correctly throughout the pipeline.
Downstream data consumption
Downstream data consumers—such as data analysts, data scientists, and business intelligence tools—rely heavily on clean, structured data for analysis. This is where data modeling comes in. A well-designed data model defines how transformed data should be consumed, ensuring optimization for query performance and understanding.
Performance and scalability
As data volume and complexity grow, data modeling also plays a key role in optimizing data pipeline performance by ensuring data can be processed and queried efficiently, especially when dealing with large data sets or complex data pipelines. A well-designed data model can account for indexing, partitioning, and query optimization, which can significantly impact the speed and efficiency of data transformations.
Data transformation challenges
As data volumes grow, transforming complex datasets efficiently becomes a major challenge. Traditional methods often struggle with scalability, data quality, and tooling inefficiencies, slowing down analytics and decision-making. Modern data transformation solutions like Coalesce address these pain points with automation, scalable workflow optimizations, and a developer-friendly approach.
Managing large data volumes
As organizations collect and process ever-growing datasets—ranging from terabytes to petabytes—efficient transformation becomes increasingly challenging. Traditional manual methods struggle to scale, leading to slow processing times, delays, or even system crashes.
Data teams can overcome these challenges by leveraging a data transformation platform built on a cloud-native architecture that dynamically scales and supports parallel processing—optimizing for incremental transformations, reducing reprocessing, and accelerating overall throughput. By automating data transformation workflows, even massive datasets are processed efficiently, minimizing bottlenecks and improving performance.
Data variety and complexity
Modern data ecosystems encompass a wide range of formats—from structured relational databases to semi-structured data in JSON or XML files, and even unstructured logs or images. Harmonizing this diverse data into a unified format is complex.
Data complexity can be simplified through robust platform integration capabilities that support multiple data types and sources. These integrations help data teams orchestrate and normalize data from disparate systems, reducing the manual overhead and potential for error that comes with managing diverse data formats.
Data quality
As pipelines become more complex, maintaining high data quality becomes increasingly difficult. Inconsistent data, missing values, and errors during collection or transformation can quickly erode trust in analytics and decision-making.
To address these issues, data teams are embedding automated data quality checks directly into their transformation workflows. This includes validation rules, profiling, and anomaly detection to catch issues early. Tools that support version control and detailed lineage also make it easier to trace and resolve problems—ensuring reliable datasets for downstream use.
Latency and real-time data transformation
In an era where organizations need insights in minutes—not hours or days—traditional batch processing can introduce unwanted delays. Increasingly, teams are turning to real-time or near-real-time data processing to power use cases like fraud detection, operational dashboards, and personalized customer experiences.
To meet these needs, teams are adopting event-driven architectures and transformation pipelines designed for continuous or micro-batch processing. These workflows reduce latency while maintaining structure, helping ensure that data is fresh, relevant, and actionable when it reaches decision-makers.
Data governance and security
As data environments grow, so do governance and compliance challenges. Teams must manage sensitive data responsibly and meet evolving regulatory standards like GDPR, HIPAA, and CCPA.
Effective data transformation strategies now include built-in governance—such as automated data classification, access controls, and lineage tracking. Embedding these features into the transformation layer ensures data is not only usable but secure and compliant from the moment it’s created or changed.
Poor data development experience (DevEx) and software tooling
Data transformation is no longer the exclusive domain of engineers with deep SQL or scripting expertise. Yet many legacy tools remain either overly complex or too rigid, limiting flexibility and slowing development cycles.
To keep pace, modern data teams are gravitating toward platforms that balance usability with power—offering intuitive UIs for speed, code-first customization for flexibility, and robust documentation and observability for long-term maintainability. A smooth developer experience makes it easier to onboard new team members, iterate faster, and build more reliable pipelines.
Data transformation: The foundation of data analytics
Data transformation is critical to the modern data analytics stack, enabling businesses to convert raw, unstructured data into clean, actionable insights. In today’s fast-paced, data-driven world, organizations need robust solutions to handle the growing complexity of their data pipelines and ensure that downstream data consumption—by data teams, AI and machine learning models, or business intelligence tools—have access to high-quality, usable data.
Scaling data transformation for large, complex data sets presents unique challenges, including handling increasing data volumes, managing diverse data formats, ensuring data quality, and reducing latency in real-time data processing. By choosing the right data transformation tool and processes, businesses can overcome these obstacles and build efficient, reliable data pipelines at any scale.
Data transformation solutions like Coalesce.io provide data teams with the modern capabilities to stay ahead of the curve and empower your team to turn data into value, faster.
Ready to Transform Your Data at Scale?
Don’t let complex data slow you down. Coalesce streamlines data transformation with automation, scalability, and built-in governance—so your team can move faster and build better pipelines.