
Organizations collect more data than ever. But simply having data isn’t enough—teams need to find, understand, and trust that data to use it effectively. This is where a data catalog comes in.
Much like a library catalog that indexes books, a data catalog indexes an organization’s data assets and key information about them. The goal is to turn scattered data into a searchable inventory of assets, so users spend less time hunting for data and more time analyzing it. In fact, research shows the average worker spends around 3.6 hours a day searching for information (and IT staff spend even more). Data catalogs can eliminate much of this wasted effort by providing a one-stop shop for data discovery and context.
In this article, we’ll explore the meaning of data catalogs and core concepts behind them, why they matter for modern data management, key features to look for, and the benefits they deliver. We’ll also discuss common use cases, types of data catalog tools (with industry examples), and how data catalogs enhance data governance and compliance. Finally, we’ll cover best practices for implementing a data catalog and why every organization—from startups to enterprises—can benefit from a unified approach to cataloging and transforming data.
Data catalog definition and core concepts
A data catalog is a centralized metadata repository that describes all the data assets across an organization. In simple terms, it’s an organized inventory of your data—databases, tables, files, reports, dashboards, and more—along with information about that data. This information (or metadata) might include descriptions of each data set, where it came from, how it’s structured, who owns it, when it was last updated, and other details that help users evaluate whether the data is fit for their needs.
Core concepts of a data catalog include:
- Metadata: Metadata is data about data—it describes where data comes from, what it contains, and how it’s used. It adds essential context to assets like data sets, documents, or dashboards. A data catalog organizes three main types of metadata: technical (e.g., schema, data types), business (e.g., definitions, owners) and operational (e.g., lineage, usage). Together, they make data easier to find, understand, and trust.
- Search and discovery: A data catalog provides intuitive search tools so users can quickly find data relevant to their task. Instead of manually asking around or combing through databases, analysts can search the catalog by keywords, filters, or facets. Modern catalogs often include AI-powered search that understands natural language queries or offers smart suggestions, making data discovery as easy as a Google search.
- Data index and inventory: Just as a library catalog lists all books available, a data catalog serves as an inventory of available data assets. It acts as a single source of reference for what data exists in the organization. This inventory function helps prevent data silos and duplication—users can see if the data they need already exists and is certified, instead of unknowingly re-creating data sets or running redundant queries.
- Data dictionary and glossary integration: A common question is how a data catalog differs from a data dictionary or business glossary. In practice, a data catalog subsumes the roles of both. It not only includes technical definitions of data (data dictionary), but also business definitions and context (business glossary). For example, the catalog can link a business term like “customer” to the various data assets (tables, reports) that contain customer information, along with the official definition and owners of that term. This ensures everyone speaks the same language and understands the data in the same way.
In summary, a data catalog is more than a static list of data sets. It’s a dynamic tool for metadata management and data discovery, bringing together the technical details and business context in one searchable hub. By combining these core concepts—comprehensive metadata, powerful search, and rich context—data catalogs enable users to quickly find trustworthy data and understand how to use it.
Why a data catalog matters for modern data management
Modern data environments are incredibly complex. Organizations store data across cloud data warehouses, data lakes, on-prem databases, SaaS applications, and streaming platforms. This data sprawl makes it challenging for anyone to know what data exists and where. Without a catalog, analysts often struggle to find the right data set, spending hours or days chasing down data owners or outdated documentation. This not only wastes time but can lead to inconsistent analysis and decision-making, as different teams might unknowingly use different versions of data.
A data catalog directly addresses these challenges, which is why it has become a critical component of modern data management:
- Breaks down data silos: In many organizations, valuable data is isolated within departmental systems or with individual team members. A catalog aggregates information about all these siloed assets into one view. This means an analyst in marketing can discover a data set created by the finance team if it’s relevant, something that might not happen without a centralized catalog. By surfacing hidden or hard-to-find data, the catalog promotes data democratization—making data accessible beyond the narrow group that created it.
- Increases productivity and efficiency: As noted earlier, a huge amount of time is lost simply searching for and prepping data. By providing a single source of truth for where data lives and what it means, a catalog allows users to find data in minutes rather than days. This efficiency gain is tangible—for example, data catalogs “improve productivity by reducing people’s time searching for data and granting them more time to analyze it.” Teams can focus on extracting insights instead of wrangling metadata and chasing down info. The result is faster project turnaround and fewer duplicated efforts across the organization.
- Improves data trust and confidence: One big reason data projects fail is lack of trust in data. If an analyst isn’t sure if a data set is up-to-date or accurate, they’ll hesitate to use it—or spend extra time verifying it. A data catalog helps establish trust in data assets by exposing information such as data quality scores, freshness, lineage, and user ratings. When users can see, for instance, that a sales report is auto-updated daily and has a high quality rating from other users, they can proceed with confidence. Conversely, if a data set has known issues, the catalog will flag that too. This transparency prevents the misuse of outdated or poor-quality data.
- Enables self-service analytics: Traditionally, business users had to ask IT or data teams to get access to data, which created bottlenecks. A data catalog empowers self-service by letting users discover and request access to data on their own. It acts as an internal data marketplace or portal: users can browse available data products, read descriptions and reviews, and then request access with a few clicks. This dramatically accelerates the pace of analysis and reduces the load on IT teams. Companies with robust catalogs often see a transformation toward a more data-driven culture, where data citizens at all levels can leverage data without heavy IT intervention.
- Supports data governance in the age of regulation: With growing regulations around data privacy and security (GDPR, CCPA, HIPAA, etc.), organizations must know what data they have and manage it carefully. It’s impossible to govern what isn’t inventoried. A catalog is foundational for compliance because it organizes and classifies data for governance. It allows applying policies (like access controls or retention rules) consistently across all data assets. For example, if certain data sets contain personal identifiable information (PII), the catalog can flag them and ensure proper encryption or restricted access. The ability to quickly find all data sets containing a certain type of sensitive information is crucial for responding to regulatory inquiries or data subject requests. In short, data catalogs provide the visibility and control needed to enforce governance in modern, distributed data landscapes.
Notably, organizations that invest in data cataloging often see broader business benefits. A study by Aberdeen Research found that companies with a data catalog experienced improvements in business outcomes—reporting growth in their customer base and higher customer satisfaction. When people can readily find and use the right data, it drives better decisions, innovation, and ultimately competitive advantage. In an era where data is a key asset, a data catalog matters because it maximizes the utility of that asset, turning raw data into usable knowledge.
Key data catalog features
Not all data catalogs are created equal. The most effective solutions offer a rich set of features that make cataloging and discovering data a seamless part of your data workflow. Here are some key features to look for in a data catalog:
Comprehensive metadata collection: A data catalog should automatically gather metadata from various sources. This includes technical details (schemas, table/column names, data types, row counts), as well as business context (descriptions, business term mappings, owners) and operational metrics (usage frequency, last updated timestamps, data lineage). Modern catalogs often integrate with databases, ETL tools, BI platforms, and data lakes to continuously harvest metadata so that the catalog is always up-to-date. The ability to catalog all types of data—structured and unstructured—is also important. For example, a good catalog will index files in a data lake or documents in cloud storage, not just databases. “Add everything to your inventory” is a best practice for cataloging, so the tool should support wide connectivity.
Powerful search and AI-powered discovery: At the core of a data catalog is its search capability. Users should be able to quickly search by keyword, apply filters (by data source, date, owner, tags, etc.), and get relevant results.
Advanced catalogs employ AI/ML techniques to enhance search—for instance, suggesting synonyms or related terms, auto-completing queries, or even allowing natural language questions (“Show me marketing campaign data from 2022”). AI can also surface popular or certified data sets higher in results. Coalesce Catalog, for example, leverages AI-powered search to put valuable data at your fingertips with lightning-fast results. An intelligent search not only saves time but also helps users discover data they didn’t even know existed (e.g., “You searched for customers—did you also know about the client onboarding data set?”). This feature turns the catalog into a true discovery engine, not just a lookup table.
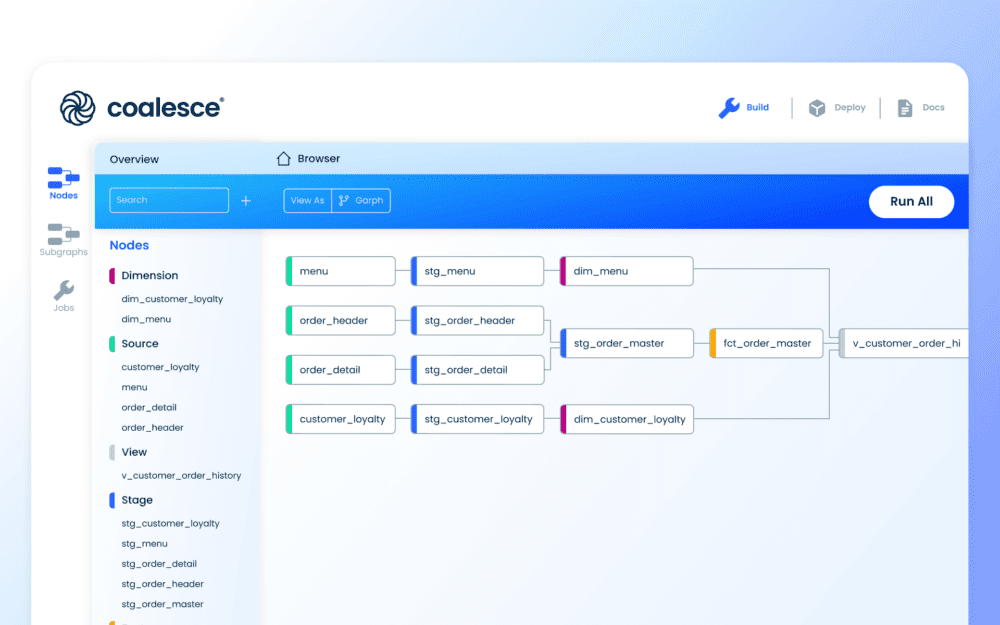
Data lineage visualization: Understanding where data comes from and how it flows is crucial for both trust and troubleshooting. That’s why data lineage is a key feature of modern catalogs. Lineage diagrams show the flow of data from source to destination—for example, a catalog can illustrate that a KPI dashboard draws from a particular table, which in turn is built from a raw data file. This end-to-end lineage (often down to the column level in advanced tools) helps users trace the origin of any data point and see all transformations along the way.
Lineage is invaluable for impact analysis (if an upstream source changes, what reports are affected?) and for auditing data usage. Platforms like Coalesce automatically map full column-level lineage across your pipelines, so every data asset’s journey is transparent. With a visual lineage graph, data engineers can quickly diagnose issues or plan changes, and data consumers can trust that they understand a data set’s provenance.

Collaboration and social tagging: Data catalogs today are collaborative platforms. They often include features inspired by social networks or wikis, allowing users to contribute knowledge. Key collaboration features include:
- User annotations and comments: Users can comment on a data set (for example, noting how they used it or cautioning about a quirk in the data). This creates a living knowledge base where tribal knowledge is captured for all to see.
- Ratings/endorsements: Some catalogs let users upvote or rate data sets, or mark a data set as a “certified” trusted source. This crowd-sourced feedback quickly highlights high-quality data assets (and discourages use of low-rated ones).
- Usage analytics: The catalog may show how often a data set is used, by whom, and in what projects. Seeing that “data set X” is widely used and referenced can signal it’s important or reliable.
- Notifications and Q&A: If someone has a question about a data set, they can ask it within the catalog, alerting the data owner or experts to answer. This ties context directly to the data. All these collaboration features turn the catalog into a living, community-driven data hub. They capture tacit knowledge and promote a data culture where people help each other find and use data effectively. (For example, an analyst might leave a note in the catalog: “Column ABC was derived using formula XYZ,” which could save the next person a lot of time.)
Automated data documentation: One of the hardest parts of maintaining a data catalog is keeping documentation up-to-date. Leading tools alleviate this by leveraging automation and even AI to assist with documentation. This can include:
- Automated metadata ingestion: As mentioned, the catalog connects to sources and pulls in technical metadata without manual entry.
- AI-generated descriptions: Using AI, some catalogs can generate initial data set summaries or suggest documentation based on the data’s patterns. For instance, an AI might detect that a column contains dates and auto-document it as “Date of purchase.”
- Continuous data profiling: The catalog might profile data (calculate statistics, detect data types or anomalies) to enrich the metadata. This gives users up-to-date info on data distributions or quality metrics.
- Version history: The catalog can track changes to metadata over time, providing a history of how definitions or schemas evolved. The result is automated, rich documentation with minimal manual effort.
Governance and security controls: Given the importance of data governance, a good catalog includes features to support governance policies and data security. This includes:
- Data classification: Ability to tag data assets or even specific fields as sensitive (e.g., PII, confidential, regulated) either manually or via automated classification algorithms. Once classified, the catalog can enforce rules (like masking or permission requirements) on those assets.
- Role-based access control and permissions: Integration with authentication systems to control who can see or edit certain catalog entries. For instance, maybe all employees can discover that a data set exists, but only authorized finance team members can see the full details or preview the data.
- Integration with data quality and lineage tools for compliance: As part of governance, catalogs often integrate with data quality tools to display data quality scores, or use lineage to ensure policies (like data retention or deletion requirements) are followed.
- Audit trails: The catalog can log user activities—who viewed what data, who updated a description, who accessed a sensitive field—which is essential for compliance audits and tracking data usage.
Modern data catalogs, including solutions like Coalesce, take governance a step further by weaving governance into the data pipeline itself. For example, Coalesce embeds governance standards directly into the transformation process—as data is ingested or transformed, it’s simultaneously classified and tagged, and access controls are applied automatically. This built-in governance means security and compliance aren’t afterthoughts; they are enforced from day one. Powerful governance tools in the catalog can ensure that data stays secure and compliant at any scale.
In summary, the key features of a data catalog span from basic inventory and search functions to advanced AI, collaboration, and governance capabilities. When evaluating catalog tools, organizations should look for a solution that not only catalogs metadata, but also actively helps users discover insights, collaborate, and maintain control. The integration of features like AI-powered search, column-level lineage, business glossary, and automated documentation (as found in Coalesce Catalog) can greatly enhance the usability and value of the catalog for all data stakeholders.
Data catalog benefits
Implementing a data catalog can yield substantial benefits across an organization. Below are some of the most important advantages and benefits of using a data catalog:
Faster data discovery and access: One of the most immediate benefits of a data catalog is the ability to drastically reduce the time spent looking for the right data. Instead of sifting through endless tables or pinging the data team for help, users can search, browse, and explore available assets in one central place. This means teams can move faster on projects and focus their time on analysis and action, rather than data hunting.
At EcoVadis, this efficiency gain was particularly significant. Facing thousands of legacy reports and duplicated dashboards, the data team used Coalesce Catalog to clean up 10,000 unnecessary reports and eliminate 30 redundant Tableau dashboards. “People are more autonomous now,” said Benjamin Raquin, Head of Data Governance. “Coalesce Catalog provides the data they need to answer most questions.” This autonomy has helped reduce noise in Slack channels and accelerated the path from question to insight across the business.
Improved data understanding and context: Data without context leads to confusion. A catalog enriches data sets with metadata, lineage, and definitions, allowing users to understand not just what data is available—but what it means, where it comes from, and how it’s used.
ManoMano tackled inconsistent definitions and scattered documentation by using Coalesce Catalog to standardize business terminology. “Before we implemented Coalesce Catalog, we had almost no documentation on our tables,” said Yoann Molina. “Now, over 80% of our main assets are documented.” The result was greater clarity, faster onboarding, and fewer misaligned KPIs.
Greater trust and data quality confidence: Trust is built when users can see data lineage, quality scores, and certification status. A catalog consolidates this information, helping teams rely on a single source of truth.
iBanFirst used Coalesce Catalog to resolve KPI discrepancies across departments. “Coalesce Catalog has become our single source of truth for data definitions,” said Fatimata Sall, Head of Data. “Now when people look for figures, they systematically ensure alignment with the definitions in Coalesce Catalog.”
Enhanced collaboration and data culture: A data catalog encourages cross-functional collaboration by allowing users to annotate, comment, and share insights. It breaks down silos and supports self-service—letting business users find answers without bottlenecking data teams.
At HomeServe France, Coalesce Catalog was central to scaling a self-service analytics culture. “It guides business users through analytics insights and helps demystify data constructs, definitions, and KPIs,” noted Thibaut Gadiolet, Chief Data Officer. “It underlies our mission to democratize data access.”
Better data governance and compliance: Governance often suffers from being invisible—or too rigid. A good data catalog makes governance seamless, embedding access policies, sensitive data tags, and audit trails directly into data workflows.
For iBanFirst, Coalesce Catalog improved compliance reporting dramatically. “We flag personal data assets in Coalesce Catalog, which I can directly report to our CISO,” said Sall. This reduced risk while maintaining operational agility.
Increased efficiency and reduced redundancy: With a holistic view of all data assets, a catalog helps eliminate duplication, reduce storage costs, and reuse high-quality data sets.
Jimdo slashed its data estate by 80% using Coalesce Catalog to identify unused tables and clarify ownership. “The platform’s ability to help us analyze dependencies and challenge teams to clean up unused assets was critical,” said Kai Richardson, Interim Data Platform Manager.
Accelerated innovation and analytics: A data catalog empowers teams to move faster—from testing hypotheses to deploying models—because trusted, well-documented data is readily accessible.
At Oodle Car Finance, this translated into a direct revenue impact. “Within three months, we rolled out changes to our loan scorecard that led to a $3M uplift,” said Mustafa Rhemtulla, VP of Data. With Coalesce Catalog, the team finally had the documentation and lineage visibility they needed to iterate quickly and confidently.
Use cases by role
A data catalog delivers value to a variety of roles in an organization. Different stakeholders will use the catalog in different ways, each with specific use cases. Let’s look at how key roles benefit from a data catalog:
Data analysts and data scientists: These data consumers are often the primary users of a data catalog. Their use case is all about fast discovery and comprehension of data. Instead of spending hours writing SQL to explore unknown tables or asking around for the right data set, an analyst can use the catalog’s search to find, say, “monthly sales by region.” The catalog returns the relevant data set, along with documentation, lineage, and perhaps even a note that “sales_by_region” is a trusted data source updated daily.
The analyst can quickly determine if it’s suitable for their needs (e.g., it has data for the required timeframe and the definitions match what they need). Data scientists, similarly, use the catalog to find features and data sets for modeling—for example, locating all data assets related to customer behavior. The catalog also helps them understand data context (so they don’t waste time with irrelevant or low-quality data). By reducing search time and providing context, the catalog lets analysts and scientists focus on actual analysis, model-building, and insight generation, boosting their productivity and effectiveness.
Data engineers and ETL developers: Data engineers are responsible for building data pipelines and preparing data for use. Their key use cases for the catalog involve understanding dependencies and ensuring data is properly documented. With a data catalog, a data engineer can easily see upstream and downstream relationships for a given data asset via lineage. For example, before altering a source table’s schema, they can check the catalog to see which dashboards or reports depend on that table—preventing accidental breakages.
Engineers also contribute to the catalog by documenting new data assets as they create them. In a modern integrated platform like Coalesce, this happens automatically: as engineers transform data, the catalog is updated with the latest metadata and lineage. This means engineers don’t have to manually create documentation in separate spreadsheets—it’s captured as part of their workflow. Another use case is impact analysis: if a data job fails or a data quality issue arises, engineers can turn to the catalog to trace issues (using lineage and metadata) and quickly identify the root cause.
Overall, the catalog streamlines data pipeline development and maintenance by providing engineers with visibility and reducing duplication. They can reuse existing trusted data sets rather than building yet another version, aligning their work with what’s already cataloged.
Data stewards and governance teams: Data stewards are tasked with maintaining data quality, consistency, and compliance. For them, the catalog is the central tool for managing and governing metadata. Their use cases include curating the business glossary, setting standard definitions for metrics, and ensuring that each important data set in the catalog has an owner, description, and quality tags.
Stewards will use the catalog’s governance features to classify sensitive fields (e.g., marking a column as containing Social Security numbers) and to enforce policies (such as who is allowed to see that column). They might configure the catalog to automatically mask or hide sensitive information from general users, as part of compliance. The catalog also provides stewards with oversight: dashboards on catalog usage can show how often data assets are used or if certain critical data sets lack documentation.
Governance teams will often use the catalog to run periodic audits—for example, listing all data sets that haven’t been accessed in over a year (potentially candidates for archival), or all assets containing personal data. By having all metadata in one place, stewards can do their job more efficiently and ensure the organization’s data meets quality and compliance standards. In platforms like Coalesce, where governance is woven into the process, stewards can even define rules that get applied during data transformation (e.g., automatically flagging any new column named “email” as sensitive). This tight integration of catalog and governance means fewer surprises and more proactive control.
Business users and managers: Increasingly, non-technical business users (like marketing managers, product managers, or executives) are leveraging data catalogs as well. Their use case is about self-service data access and understanding without needing deep technical skills. A business user might log into the data catalog’s web interface and search for a KPI or report—for instance, “customer churn rate Q4.” The catalog could return an entry for a churn analysis dashboard or data set, complete with an explanation of how churn is calculated and who to contact for more details. This saves the business user from having to request data from the BI team and wait.
Business teams can get quick answers, or at least know where to find the data for their decision-making. Additionally, business users benefit from the data literacy that a catalog provides. They can explore the glossary to learn definitions of terms (making meetings between business and data teams more productive, since everyone uses the same definitions). They can also trust that the data they pull from the catalog is the official data (for example, the sales figures in the catalog are the ones finance has approved, not some ad hoc numbers).
In essence, the catalog acts as a data concierge for business users, guiding them to the right information and reducing miscommunication. Some organizations even use the catalog to enable a data request workflow, where a business user finds a data set and clicks “Request Access,” triggering an approval process that the data steward oversees. This streamlines the once time-consuming task of data provisioning into a self-service experience.
Chief Data Officers (CDOs) and data leaders: For data leaders, a data catalog provides a high-level overview and control mechanism over the organization’s data assets. Their use case is focused on strategic oversight. Through the catalog, a CDO can get a catalog-wide view of data asset inventory, identify gaps (e.g., critical systems not yet cataloged), and monitor adoption metrics (how many active users? how many assets have complete documentation?). This helps in demonstrating the value of data initiatives.
If a CDO wants to drive a data governance program, the catalog is the natural place to do it, by setting up governance policies and measuring compliance via the catalog. Additionally, data leaders use the catalog to ensure alignment between data strategy and data usage. For instance, if the company’s strategy is to be AI-driven, the CDO will check that the key data needed for AI projects is well cataloged and accessible to the data science team.
The catalog becomes a tool to identify opportunities (such as data that could be repurposed for new revenue streams) and to prevent risks (spotting if sensitive data is overexposed). Essentially, the data catalog is a dashboard for data leadership to keep a pulse on the health and utilization of the company’s data assets.
As we see, a data catalog serves everyone from hands-on data workers to strategic decision-makers. By tailoring the experience to each role—whether it’s quick search for analysts, governance control for stewards, or self-service for business users—a good catalog becomes an indispensable part of daily operations. Modern platforms like Coalesce recognize this by creating features like natural language search and AI assistants that “help everyone get detailed answers to their data-related questions” in a user-friendly way. This ensures that every data person, technical or not, can be on the same page when it comes to understanding and leveraging the organization’s data.
Types of data catalogs & tools
As the demand for data catalogs has grown, various types of catalog tools have emerged. Organizations can choose from a range of solutions, from commercial platforms to open source projects, depending on their needs. Here we outline the main types of data catalogs and examples of tools in each category:
Enterprise data catalog platforms: These are dedicated catalog solutions, often offered by specialized vendors. They focus on providing a full suite of cataloging features out-of-the-box. Such platforms are typically technology-agnostic, meaning they can connect to a wide variety of data sources (databases, big data platforms, BI tools, etc.). They often excel in rich features like advanced metadata search, collaboration functions, workflow for stewardship, and integration with data governance and quality tools.
Organizations with diverse data ecosystems often use these as a central pillar of their data management strategy.
| Pros | Cons |
| Rich functionality, integrations, and vendor support. | They can be complex to implement and may require significant investment and integration effort. |
Cloud-native data catalogs: With so much data moving to the cloud, all major cloud providers offer their own cataloging services tightly integrated with their platforms. These cloud-native catalogs are great if your data resides mostly within one cloud environment, as they auto-harvest metadata from that cloud’s services and offer seamless security integration. They can also be very scalable, handling big data volumes common in cloud data lakes.
However, they might be less ideal if you have a multi-cloud or hybrid setup, or need the deep cross-system capabilities of standalone platforms.
| Pros | Cons |
|
|
Integrated data platform catalogs: Some modern data platforms and tools come with built-in catalog functionality. Rather than being a separate product, the catalog is part of a larger data management or data analytics platform.
Coalesce is a great example here—it’s a data transformation platform that includes an AI-powered data catalog natively integrated into the development environment. This means as you build your data pipelines in Coalesce, the platform is automatically documenting and cataloging those data assets in real time. With Coalesce, catalog and transformation are in one place, which simplifies governance by weaving it directly into your data transformation process.
Another example is Databricks, which has a feature called Unity Catalog for managing metadata and governance across its Lakehouse platform. Integrated catalogs like these offer the advantage of unifying data cataloging with other workflows so users don’t have to jump between multiple tools.
| Pros | Cons |
|
|
Open source data catalogs: For organizations that prefer open source solutions (to avoid vendor lock-in or for cost reasons), there are several community-driven data catalog projects. Open source catalogs can be quite powerful and customizable, but typically require more internal expertise to deploy and maintain. They might not have all the polish or support of commercial tools, but they benefit from community contributions and flexibility.
| Pros | Cons |
|
|
Specialized catalog tools: Some catalogs specialize in particular niches. For example, there are catalogs built into BI tools (Power BI has a data cataloging feature for its data sets, Tableau has a cataloging feature in its Server/Online for the data sources used in dashboards). These are focused on the analytics layer. There are also domain-specific catalogs, such as genomic data catalogs in healthcare or geospatial data catalogs for GIS data—often part of larger domain-specific data management systems.
| Pros | Cons |
|
|
One catalog to rule them all? Not quite.
Often, an organization might use a combination of these. For instance, a company could use a standalone enterprise catalog to cover overall metadata management, but also leverage a cloud-specific catalog for deep integration within a cloud warehouse, and possibly an integrated platform like Coalesce for specific teams who are building data pipelines rapidly and want automated documentation. The good news is many of these tools can connect—e.g., Coalesce’s catalog could feed into an enterprise catalog via APIs, or an open source catalog can ingest metadata from cloud services.
When considering tools, it’s important to evaluate factors like: ease of integration (with your databases, ETL jobs, etc.), user experience (for the people who will search the catalog), governance capabilities, and how well the tool aligns with your data stack. Well-known examples in the market include Alation, Collibra, IBM Watson Catalog, Informatica, Azure Purview, AWS Glue, Google Data Catalog, Atlan, DataGalaxy, Data.World, Amundsen, and Coalesce Catalog. Each has its strengths, and the “best” choice depends on your specific needs—some prioritize collaboration, others automation, others tight security integration, etc.
One trend worth noting is the move toward unified platforms that combine cataloging with other data management tasks. Coalesce’s approach of marrying data transformation with cataloging is one such example, aiming to eliminate silos between where data is created and where it’s documented. This indicates that the future of data catalogs might be less about a separate tool and more about an integrated capability that’s part of every layer of the data stack.
How data catalogs enhance governance and compliance
In an era of stringent data regulations and heightened privacy concerns, the role of data catalogs in data governance and compliance is paramount. By centralizing metadata and providing oversight mechanisms, data catalogs make it significantly easier to govern data and ensure compliance with internal policies and external laws. Here are ways in which a data catalog enhances governance and compliance:
Centralized data classification: A catalog allows organizations to systematically classify data assets. For example, using the catalog, data stewards can tag data sets or specific fields as Sensitive, PII (Personally Identifiable Information), Financial Data, Public/Private, etc. Some catalogs use automated scanning (sometimes with AI) to detect sensitive information (such as email addresses or credit card numbers) and flag them.
Once data is classified in the catalog, rules can be applied uniformly. This is vital for compliance regimes like GDPR, which require knowing where personal data is stored and processed. With a catalog, a company can quickly generate a list of all assets containing personal data and ensure proper measures (encryption, limited access, consent tracking) are in place.
Role-based access control and data security: Data catalogs often integrate with Identity and Access Management (IAM) systems or have their own permission models, enabling fine-grained access control over data assets. For instance, you might allow all analysts to see metadata for a certain database in the catalog, but only authorized HR personnel can see the contents or details of the “employee_salary” table entry.
By governing access at the catalog level, you add an extra layer of security: even if someone finds a data set in the catalog, they know they must request access to actually retrieve the data if they aren’t already permitted. Moreover, catalogs can provide auditing of access requests—recording who requested what data and whether it was approved, creating an audit trail for compliance. In advanced scenarios, the catalog can even serve as the gatekeeper, enforcing that only compliant access happens (some catalogs tie into data virtualization or masking tools to enforce row-level or column-level security as users access data through the catalog interface).
Data lineage and impact analysis for compliance: Regulatory compliance often requires demonstrating control over data lineage—knowing where data came from, where it goes, and who/what has touched it. A data catalog with robust lineage capabilities provides this transparently.
For example, consider a regulation that mandates the ability to “forget” a user’s data upon request (a right to erasure). With a catalog lineage graph, you can trace that user’s data from the source (say a CRM system) through all downstream systems (data lake, analytics DB, reports) and ensure that their data is removed or anonymized everywhere. Without a catalog, such a task could be nightmarish, potentially missing some data stores.
Similarly, if a data breach occurs, lineage helps quickly assess what systems were impacted and what sensitive data might have been exposed. Essentially, lineage is a compliance lifesaver for tasks like impact assessments, audit reporting, and disaster response. Regulators and standards (like BCBS 239 in finance or various ISO data standards) emphasize lineage and traceability, which a catalog inherently provides.
Policy enforcement and data masking: Many modern catalogs don’t just catalog policies; they help enforce them. For instance, a governance team can define a policy in the catalog that “Customer PII data must be masked for non-production use.” Through integration with data pipeline tools or query engines, the catalog can ensure that any data set tagged as PII automatically gets masked when accessed in a lower environment or by a user without proper clearance.
IBM’s Watson Knowledge Catalog and others have such policy-driven automation, where catalogs tie into data integration processes to enforce compliance rules at runtime. Even if enforcement isn’t directly through the catalog, just having the policies documented and visible in the catalog is a big win—a data set might have an attached policy note that reads “Finance data: do not share externally,” which any user will see before using the data. This reduces accidental misuse and keeps everyone aware of the dos and don’ts for each data asset.
Audit trails and accountability: Every action in a good data catalog can be logged—adding a data set, editing a description, viewing an entry, etc. Such audit trails mean you can answer these kinds of questions: Who last updated the definition of this field? Who accessed the customer data last week? When was this classification changed and by whom?
This level of transparency and accountability is crucial for governance. It deters unethical behavior (since people know actions are logged) and provides a forensics tool in case of incidents. For compliance, being able to produce audit logs of data access and changes can demonstrate to regulators that you have control over your data environment. It’s much easier to do this via a catalog’s logs than to try to aggregate logs from dozens of different databases and tools.
Standardization and elimination of shadow data: By promoting a single catalog as the authoritative source of metadata, organizations encourage teams to use the centralized, governed data rather than creating rogue spreadsheets or shadow systems. This centralization is itself a governance benefit—it’s easier to govern one known environment than to chase down ad hoc data stores. A data catalog essentially serves as the catalog of record.
When everyone knows to look at the catalog for the official definition of a metric or the approved source of a certain data feed, it reduces the proliferation of conflicting information. Consistent use of the catalog thus enforces standards and reduces the chance of non-compliant data copies floating around.
In practice, companies that have implemented data catalogs as part of their governance framework report significantly smoother compliance processes. For example, rather than scrambling for weeks to fulfill an auditor’s request, they can often answer via the catalog in minutes (like producing a list of users with access to financial reports, along with proof of data quality checks). Governance and catalog go hand in hand: “Data catalogs are a technology to implement data governance policies,” effectively operationalizing governance. Coalesce’s philosophy of embedding governance into the transformation process is a prime example of how tightly these can be coupled, ensuring that as data is created and changed, governance is inherently applied.
In summary, a data catalog acts as the backbone of data governance. It provides the visibility, control, and mechanisms needed to manage data responsibly. Whether it’s meeting legal obligations or internal data ethics standards, the catalog is an indispensable tool to help organizations stay compliant while still enabling broad and productive use of data.
Best practices for implementing a data catalog
Successfully implementing a data catalog in an organization involves more than just installing a tool. It requires thoughtful planning, ongoing management, and cultural change. Here are best practices for implementing a data catalog to maximize its adoption and impact:
Inventory all your data assets: Start by capturing the full scope of data that should be cataloged. This includes obvious sources like databases and data warehouses, but don’t forget about spreadsheets, documents, data lake files, APIs, and even external data sets the organization uses. Add everything to your inventory—you can always prioritize later, but you should know what’s out there. Conduct interviews or surveys with teams to discover hidden data stores. The more comprehensive your catalog’s coverage, the more useful it will be (and the less likely people will go elsewhere for data).
Engage stakeholders and define roles: A data catalog is not solely an IT project; involve business users, analysts, data scientists, data stewards, and executives early on. Identify data stewards or owners for different subject areas who will be responsible for curating and approving metadata in the catalog.
Define clear roles like who can add/edit metadata, who approves glossary definitions, who manages access rights. When people have assigned responsibilities (e.g., each domain has a steward), the catalog content will be better maintained. Executive sponsorship is also crucial. Leaders should champion the catalog as the “go to” place for data and encourage their teams to use it. This cross-functional approach ensures the catalog reflects both technical and business perspectives.
Establish a common business vocabulary: Before or during catalog implementation, develop a business glossary of key terms and metrics. This might involve workshops with business units to settle on standard definitions (for example, agreeing on what counts as an “active user” or how “revenue” is calculated). Feed these definitions into the catalog’s glossary feature and link them to data assets.
By having a vetted glossary, you prevent confusion when users search the catalog and encounter terms. Maintaining this glossary is an ongoing process; assign owners to each term to update definitions as business concepts evolve. A shared vocabulary greatly enhances the catalog’s value by ensuring everyone interprets data consistently.
Prioritize critical data & sensitive information: Not everything can be documented perfectly on day one. Prioritize cataloging the most important and high-impact data assets first—typically the data feeding into key reports, dashboards, and analytical use cases that drive business decisions. Simultaneously, prioritize cataloging sensitive data (customer information, financial data, etc.) for governance reasons.
By focusing on critical and sensitive data first, you mitigate the highest risks and deliver quick wins (users will immediately find value since the important stuff is cataloged). You can phase in less critical data over time. Also, as you catalog sensitive data, apply proper tags and policies up front, so compliance is baked in from the beginning.
Automate metadata ingestion and lineage: Leverage the technology capabilities of your data catalog tool to automate as much as possible. Set up connectors to your databases, ETL tools, BI platforms, etc., so the tool can continuously pull in schema changes, new tables, and updated lineage. This automation ensures the catalog stays current without requiring someone to manually update it every time something changes (which is not scalable).
It’s also wise to schedule regular metadata refresh jobs and to integrate the catalog with your data pipeline CI/CD process, so any new data deployment updates the catalog as a step in the pipeline.
Encourage user adoption and contribution: A data catalog only thrives if people use it and contribute to it. Drive adoption by integrating the catalog into daily workflows. For example, embed catalog search in your team’s data portal or Slack (so people can query it easily), or incorporate catalog links in your BI dashboards (“View data lineage”). Conduct training sessions and demos to show analysts and others how to use the catalog effectively—many people will need to learn the habit of searching the catalog first.
Incentivize contributions by applauding teams or individuals who heavily document their data sets or answer questions on the catalog. Perhaps create a recognition program for “Data Steward of the Month” to reward good catalog practices. Also, collect feedback from users and improve the catalog iteratively—if users find the interface clunky or the search not yielding expected results, refine it.
The more the catalog feels like a helpful friend rather than extra homework, the more people will embrace it. Cultivating a community (maybe via an internal champions group or a forum for catalog users) can also help maintain momentum.
Maintain and continuously govern: Implementation isn’t a one-time project—allocate ongoing resources for catalog maintenance and governance. This includes:
- Regular audits: Periodically review catalog content for stale entries (e.g., data sets that no longer exist or have outdated info) and clean them up. Ensure each critical asset has an owner, description, and is properly tagged.
- Quality control: Use the catalog’s built-in metrics or reports to monitor completeness of metadata (what % of tables have descriptions? how many glossary terms are linked?). If certain areas are lagging, assign stewards to fill the gaps.
- Upgrade and integrate: Keep the catalog tool updated to benefit from new features, especially as your data environment changes (new systems may need integration). If you adopt new data platforms, include them in the catalog integration plan.
- Governance reviews: Have the data governance committee (or equivalent) periodically review the catalog’s role in compliance. For example, ensure that new regulatory requirements are reflected (like adding a tag for “CCPA relevant” if needed). Use the catalog’s audit logs to conduct spot checks on data access and usage patterns.
- Promote success stories: To keep engagement high, share stories internally of how the catalog helped a project (e.g., “The finance team saved two weeks by reusing data from the catalog that the marketing team had already documented”). Success breeds success—as colleagues hear how the catalog makes life easier, they’ll be more inclined to leverage it.
By following these best practices, organizations can avoid common pitfalls (like a “empty” catalog that nobody uses or a quickly outdated one) and instead build a sustainable, valuable resource. It’s worth noting that implementing a data catalog is as much about people and process as it is about technology. Change management, training, and ongoing stewardship are key.
When done right, a data catalog becomes a self-reinforcing asset: the more people use and contribute to it, the more valuable it becomes, which in turn attracts even more use—a positive feedback loop for data-driven success.
Conclusion: Why every organization needs a data catalog
In conclusion, a data catalog is no longer a “nice to have” for organizations that deal with data—it’s quickly becoming an essential component of the modern data stack. Whether you’re a small startup or a global enterprise, if you have multiple data sources and users who need to analyze data, a data catalog provides the map to your data treasure. It brings order to chaos by organizing data assets, adds rich context that empowers users, and ensures that data governance is upheld even as data scales and regulations tighten.
The benefits of a data catalog ripple across the organization: faster insights for analysts, more efficient pipelines for engineers, stronger data ownership and quality for stewards, and greater confidence in decisions at the executive level. By implementing a catalog, companies set the foundation for a truly data-driven culture—one where data is readily accessible, well understood, and trusted by everyone who needs it. In a competitive landscape, the ability to quickly find and leverage the right data can be a game-changer, enabling everything from personalized customer experiences to AI-driven innovations.
Unlock the full value of your data with Coalesce’s AI-powered data catalog
Tired of wasting hours searching for reliable data? Coalesce Catalog delivers instant visibility, column-level lineage, and AI-powered discovery—right inside your transformation workflow. See how it works in action.