Data mesh architecture has been one of the most talked-about topics in the data industry in recent years, sparking both excitement and skepticism in equal measure. Advocates highlight its potential to transform how organizations manage and scale data, promising a decentralized approach that can drive more efficient collaboration, faster decision-making, and better data products.
On the other hand, many organizations have encountered difficulties in implementing data mesh, leading some to question whether it’s just another over-hyped trend or a legitimate solution to the industry’s growing data challenges.
In this article, we’ll dive into data mesh concepts and core principals. We’ll also discuss when it makes sense to implement, why some companies have struggled with adoption, and the steps you can take to adopt it successfully.
What is data mesh?
Data mesh is a decentralized data architecture approach where domain teams own their data as products, enabling self-service access while maintaining federated governance. This paradigm shifts data ownership from centralized teams to domain experts who understand the business context. The initial idea was conceptualized and popularized by technologist Zhamak Dehghani.
Unlike traditional data architectures, where centralized teams manage and govern data for the entire organization, data mesh architectures focus on shifting responsibility to the domain teams who know the data best. Each team or domain becomes responsible for creating, managing, and sharing high-quality data products. These products are designed to be easily consumed by other teams within the organization.
The goal is to make data more accessible, collaborative, and useful by leveraging the expertise and context of each domain, rather than relying on a centralized data team. By decentralizing ownership and encouraging cross-team collaboration, data mesh aims to make data a more integral part of business decision-making.
The promise and reality of data mesh
While data mesh holds significant promise, it’s important to approach it with a realistic mindset. It’s not a one-size-fits-all solution, and for some companies, it may not be the right fit—especially if they lack the appropriate infrastructure and resources to support it.
Before jumping into implementation, organizations need to understand what data mesh is, why it’s useful, and when and where it makes the most sense. A key factor behind the slow adoption of data mesh has been the lack of the right technology to enable it, a challenge that’s only recently starting to be addressed.
For more on this, you can check out our article on the technology crucial for successfully implementing data mesh.
Why is data mesh important?
1. Vast amounts of data
Organizations today are collecting vast amounts of data from various sources—sales, customer behavior, website interactions, operational processes, and more. However, just collecting data isn’t enough; the real value comes from making this data actionable.
2. Challenges leveraging data for decision-making
Business stakeholders and domain owners often find it difficult to leverage all the available data effectively. The data can be fragmented, siloed, and difficult to access, making it challenging to extract meaningful insights and make informed decisions. With so much data at their fingertips, stakeholders are often overwhelmed and unable to use it to steer business initiatives or drive growth.
3. The old approach is no longer effective (or efficient)
Historically, data management has followed a centralized approach, where a dedicated data team controls data pipelines and access to data. While this model has its merits, it creates bottlenecks that prevent teams from getting timely data.
Ad hoc requests, maintenance issues, and pipeline firefighting often overwhelm the centralized data teams, leaving business domain teams unable to use data effectively when they need it.
This centralized model also leads to a “same data, different answer” problem, where different teams or individuals analyze the same data and come to different conclusions. This inconsistency creates confusion and undermines trust in the data.
4. Solving critical data and business problems
Data mesh aims to address these challenges by decentralizing data ownership. By giving domain teams control over their own data and pipelines, data mesh encourages collaboration and ensures data is aligned with the business context.
Each team is responsible for building and managing data products that are easily consumable and shareable across the organization. This model reduces the reliance on a central data team, which allows for faster decision-making, more effective use of data, and higher-quality data products.
Imagine a manufacturing floor where workers are constantly switching between tasks. That’s the reality of a centralized data team, spread thin and constantly shifting focus. Now picture a factory where each worker owns a specific process. They become experts, optimizing for efficiency and delivering a superior product. That’s the transformative power of a decentralized data mesh.
Core principles
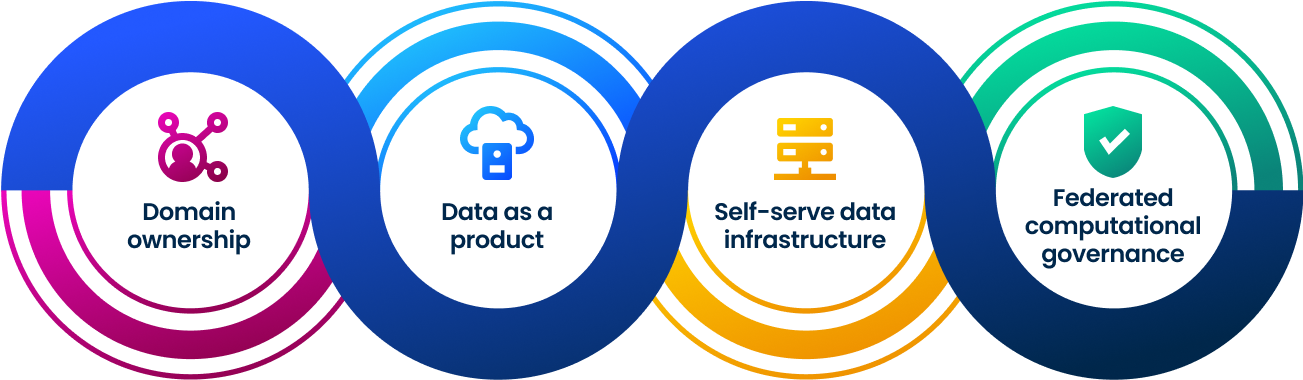
To implement data mesh successfully, organizations need to adhere to a set of guiding principles:
Source: Data mesh: a new paradigm for data management
1. Domain ownership
The key principle of data mesh is that domain teams should own the data they produce. These teams are closest to the data and understand its nuances and context. By decentralizing ownership, data mesh encourages domain teams to treat data as a product and take responsibility for its quality, accessibility, and usability.
2. Data as a product
In a data mesh, data is treated like any other product. Domain teams are responsible for creating data products—structured, well-defined data sets or analytics—that are easy to consume by others. These products should be reliable, high quality, and designed with the needs of end users in mind.
3. Self-service
Data mesh enables teams to easily access and interact with data products through the use of self-service data platforms. Rather than relying on a central team to provide data on request, domain teams can independently access the data they need, accelerating decision-making and reducing bottlenecks.
4. Data governance
Despite decentralization, data governance remains a critical aspect of data mesh. Clear standards and guidelines should be in place to ensure data quality, security, privacy, and compliance. This can be done through the use of a governance team with members from each domain involved. In this way, governance in a data mesh model is decentralized but coordinated, ensuring that each domain team adheres to common standards and practices while still maintaining flexibility.
Benefits
The implementation of data mesh offers several key benefits that can transform how organizations use and manage their data:
1. Improved collaboration between domain and data teams
Data mesh encourages domain teams to work together, share data, and collaborate more effectively. By treating data as a product, teams gain a better understanding of how their data can be used by others, leading to greater collaboration and alignment across departments.
2. High-quality data products
With ownership of their data, domain teams are motivated to create high-quality, reliable data products. These products are tailored to the needs of other teams, reducing the friction of accessing data and ensuring that it’s easy to consume and use in decision-making.
3. Faster data project delivery
By decentralizing data management, data mesh reduces the burden on central data teams, allowing them to focus on high-priority projects. This leads to faster development of data projects and reduces the time required to build and maintain data pipelines.
4. Eliminate redundancy and “rogue” data projects
In a traditional centralized model, there’s often duplication of efforts across teams, with multiple teams working on similar data initiatives. Data mesh eliminates this problem by encouraging domain teams to work more closely together and align their data initiatives, reducing redundancy and avoiding rogue data projects.
5. Improved data culture
Data mesh fosters a culture of trust, collaboration, and curiosity around data. By decentralizing data ownership, it encourages teams to take responsibility for the data they produce, leading to greater accountability and a more data-driven culture across the organization.
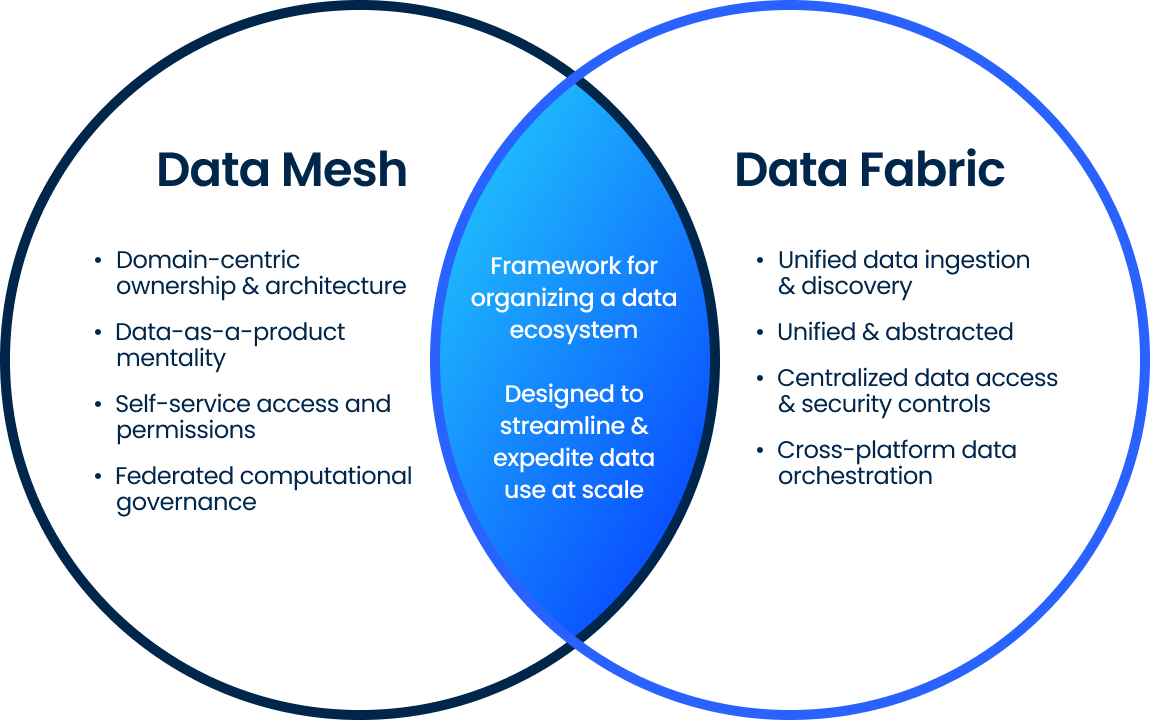
Data mesh vs. data fabric: What’s the difference?
While data mesh and data fabric are often discussed together, they are distinct concepts. Data mesh is an organizational and architectural approach to data, while data fabric is a technical solution for managing and integrating data.
- Data mesh focuses on decentralizing data ownership and enabling domain teams to manage their own data as products. It emphasizes organizational change and a new way of working with data.
- Data fabric, on the other hand, is more about technology. It provides an integrated layer of data management tools and services that help organizations manage and access data across a variety of systems and platforms. Data fabric focuses on data connectivity, integration, and automation.
Source: Data Mesh vs. Data Fabric Architectures
When does data mesh implementation make sense?
Data mesh isn’t for every organization. However, certain factors can help determine whether it’s the right solution for your business:
1. Data team and bandwidth
If your data team is overwhelmed with ad hoc requests and struggling to meet the needs of business stakeholders, data mesh could be a solution to decentralize responsibilities and improve efficiency.
2. Number of data sources
The more data sources you have, the more complex your data management becomes. Data mesh can help address the challenges of managing large and diverse data sets across different domains.
3. Company size and domains
Larger organizations with multiple departments or domains may benefit from data mesh, as it decentralizes ownership and gives each domain team more control over their data.
4. Data “appetite” and culture
If your organization has a strong desire to make data a central part of decision-making and collaboration, and if there’s an emphasis on cross-team cooperation, data mesh may be a good fit.
5. Data principles and culture
Does your organization value collaboration, data quality, and self-service? If so, data mesh may align with your data culture and enhance your ability to use data more effectively.
Why adoption hasn’t taken off (yet)
Despite the growing interest in data mesh, its widespread adoption has been slower than expected. Some common pitfalls include:
Technical limitations: Earlier solutions for implementing data mesh lacked flexibility and were built for a narrow subset of highly technical data practitioners, not the broader organization.
Complexity: Data mesh requires a cultural shift and significant changes to organizational workflows, which can be a roadblock for some companies.
Governance challenges: Maintaining data standards across decentralized teams can be difficult without the right tools and processes in place.
However, many of these technical limitations have been cleared, and tools like Coalesce are making it easier to implement data mesh successfully. Companies like Paytronix have successfully implemented data mesh architectures.

Implementation
Implementing data mesh isn’t without its challenges—there are technical hurdles, cultural shifts, and organizational changes to consider. Success requires careful planning and the alignment of key stakeholders.
With the right technology, resources, and mindset, data mesh can transform how your organization manages and leverages data. Here are some steps to get started:
1. Define the use case and requirements
Identify the challenges you’re facing with your current data architecture and how data mesh can help. This includes defining the benefits, requirements, and potential roadblocks for your organization.
2. Get buy-in
Secure support from key decision-makers, including business and domain leaders, to ensure alignment across the organization.
3. Choose a proof of concept (PoC) project
Start with a specific domain or use case that would benefit from data mesh, and use it as a pilot project to test the approach.
4. Educate domain teams
Ensure that domain teams are equipped with the knowledge and software tools to manage their own data pipelines and products effectively.
5. Scale gradually
Once the PoC project is successful, expand the data mesh model to other domains and teams gradually.
Watch the full episode of our podcast, Data Mesh with Una Galyeva, to learn more about the reality of data mesh implementations versus the theoretical concepts. Data and AI consultant Una Galyeva dives into use cases where implementing data mesh makes sense, assembling the right team for a successful transition to a data mesh structure, and more.
The future of data mesh and the role of AI
As enterprises continue to generate vast amounts of data, fueled in part by rapid advancements in AI and machine learning, the need for scalable, decentralized data management strategies will only grow. Data mesh is poised to become a critical framework for effective decision-making and maximizing the value of data. By decentralizing data ownership and enabling domain teams to manage their own data products, organizations can break down silos and accelerate the flow of data across departments.
The key to success will lie in adopting solutions that not only address these challenges but are also user-friendly and efficient, enabling teams to build quality data products quickly and scale them as needed.
In the years to come, data mesh, supported by AI-driven tools and platforms, will become a standard for organizations looking to unlock the full potential of their data. Companies that embrace this decentralized strategy will uncover tremendous opportunities to improve collaboration, reduce bottlenecks, and create a more agile, data-driven culture.
Go from data mess to data mesh with Coalesce
Decentralize data ownership across your organization by giving every data expert the ability to create and consume data products.