Data is one of the most valuable resources a business has—but raw data on its own isn’t very useful. To make data impactful, you need to clean, shape, and organize it so teams can use it to make decisions. This process—called data transformation—has become a key part of working with data in Snowflake.
Snowflake supports an ELT approach (Extract, Load, Transform), where raw data is loaded first, then transformed using SQL. This setup makes it easier to create and manage data logic as needs change, and it uses Snowflake’s flexible compute power to handle large workloads.
Today’s data workflows go beyond loading, transformation, and querying. They often include both real-time and batch data, multiple tools, and require built-in governance and performance tuning. As Snowflake puts it, the “T” in ELT—transformation—is becoming more advanced. More data sources, more users, and more use cases mean teams need clear strategies for managing their data.
This guide breaks down the core concepts behind transforming data in Snowflake. It also shares best practices, advanced techniques, and what’s ahead. You’ll also see how companies using Coalesce are getting value from their data faster. By the end, you’ll know how to design data transformation pipelines in Snowflake that are efficient, flexible, and built for what’s next.
What is Data Transformation in Snowflake?
Data transformation is all about turning raw information into something clean, structured, and ready for business use—whether that’s analytics, reporting, or integrating with other systems. In Snowflake, this typically involves using SQL to take messy, varied data and turn it into consistent, reliable tables.
Snowflake supports both traditional ETL (Extract, Transform, Load) and modern ELT (Extract, Load, Transform). But it’s especially optimized for ELT workloads. This approach gives teams flexibility to create and manage logic over time and uses Snowflake’s powerful cloud infrastructure to process large volumes of data efficiently.
In practice, transformation in Snowflake covers a wide range of tasks. You might need to clean data (like handling missing values), apply business rules (such as currency conversions), or combine and reshape data from different sources. These steps are often written as SQL queries, whether you’re building a new table, updating an existing one, or creating a view for reporting.
Snowflake handles all of this at scale thanks to its elastic compute and parallel processing. And while SQL is the default language, you can also use higher-level tools—like Coalesce—that work on top of Snowflake to make transformation easier and more visual.
Importantly, Snowflake doesn’t force you into one specific process. You can transform data as it’s coming in or after it lands. You can write raw SQL, use a platform like Coalesce, or even securely share data between teams without needing to transform it at all.
In short, Snowflake gives you the flexibility and power to manage data transformation your way—whether you’re just getting started or building for scale. The next section covers the core building blocks that help make that possible.
Fundamental concepts of data transformation in Snowflake
Designing an effective Snowflake data transformation strategy starts with understanding how the platform works. Snowflake offers unique features—like scalable compute, flexible storage, and native SQL support—that help teams build transformation workflows that are reliable, cost-efficient, and easy to manage.
Separation of storage and compute
A key strength of Snowflake is how it separates data storage from compute. All your raw and transformed data is stored in one central place, while compute power—called virtual warehouses—can be turned on or off as needed.
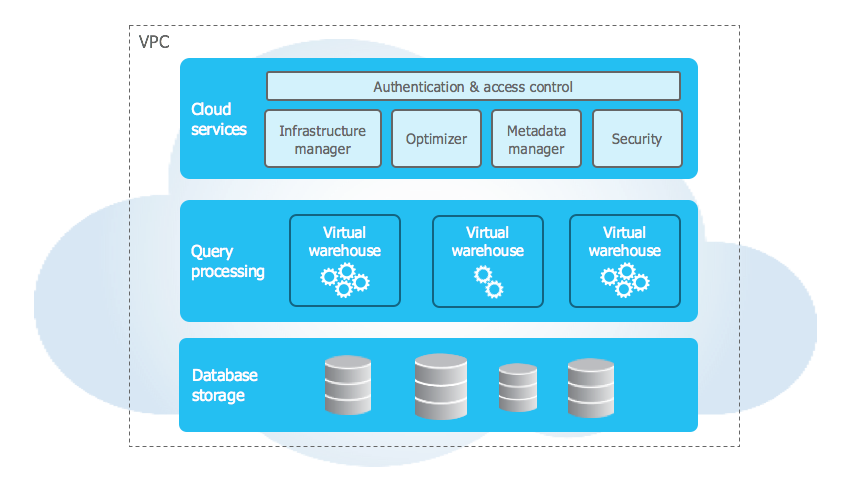
For example, you might spin up a large warehouse to process a heavy transformation job, then shut it down immediately after. This flexibility means you only pay for compute when you use it, and you can scale resources based on the size of the job, not the size of your team.
Recently, Snowflake announced new Gen 2 Virtual Warehouses that deliver faster performance, smarter scaling, and better cost efficiency for modern data workloads. Designed to handle everything from high-concurrency BI dashboards to complex data transformations, Gen 2 (or next-generation standard warehouse) reduces query latency and improves throughput without the need for constant tuning.
Teams can do more with less compute, thanks to enhanced workload management and intelligent caching. It’s a major leap forward for anyone building data products, pipelines, or AI-ready infrastructure on Snowflake.
Organizing your data with schema design
Well-structured data makes transformations easier. Many teams adopt a layered schema approach aligned with data mart architecture to promote clarity and reuse.
- The raw layer stores data exactly as it arrives from the source.
- The staging layer standardizes, cleans, and reshapes the data.
- The intermediary layer joins, enriches, and organizes data across domains.
- The mart layer contains curated, business-ready datasets optimized for analytics, dashboards, or machine learning.
This layered setup simplifies troubleshooting, promotes reusability, and makes it easier to understand how data flows through your system. When designing for analytics in Snowflake, denormalized structures like star or Snowflake schemas can further enhance performance.
Loading data and preparing for transformation
Before you can transform data, you need to load it. Snowflake supports both batch loads (using the COPY INTO command) and continuous loading through Snowpipe. You can also apply light pre-processing during this step—such as cleaning up empty values or standardizing column types—to catch issues early.
Once data lands in a raw table, staging tables can help organize and prepare it for more complex transformations. Features like Time Travel and zero-copy cloning allow you to test changes safely and roll back if needed.
It’s worth noting that loading data into Snowflake isn’t restricted to custom scripts or manual ETL jobs. Tools like Fivetran offer automated, connector-driven ingestion that simplifies the extract-and-load process from dozens of sources—including SaaS apps, databases, and event streams. These tools are purpose-built for ELT, landing raw data directly into Snowflake with minimal setup and ongoing maintenance.
Once the data lands, platforms like Coalesce pick up where ingestion leaves off. Through native integrations with tools like Fivetran, Coalesce can detect schema changes and trigger downstream transformations automatically—turning raw data into analytics-ready tables in near real time. This seamless handoff between ingestion and transformation ensures your data pipelines stay fresh, resilient, and responsive to changes across your source systems. The result? A highly automated and scalable data architecture that reduces lag, improves data reliability, and accelerates time to insight.
Writing transformations with SQL and views
SQL is at the heart of Snowflake data transformation. You’ll typically use it to filter, join, or calculate new columns. Often, transformations are written into views—saved queries that update automatically whenever they are executed.
If speed is a concern, you might use a materialized view instead, which stores the result for faster access. For example, if your team checks yesterday’s sales data multiple times a day, a materialized view can avoid re-running the same heavy query.
One of Snowflake’s key strengths is how it handles both structured and semi-structured data—like JSON or XML—without needing to reformat everything upfront. Its VARIANT data type makes it possible to store and query this kind of data directly using SQL. That means fewer tools, simpler workflows, and faster results.
Automating workflows with Streams and Tasks
Snowflake includes built-in automation tools to help run transformations on a schedule or in response to new data. Streams track changes—like new or updated records—on a table. Tasks run SQL or stored procedures at regular intervals or in sequence.
Combined, they allow you to set up transformation pipelines that update in near real time. For example, a retail team might use a stream to detect new sales and a task to update a revenue summary table every 15 minutes.
Extending logic with UDFs and Snowpark
For more complex logic, Snowflake supports user-defined functions (UDFs) and stored procedures written in SQL, JavaScript, or Python. These let you reuse custom rules or calculations across your transformations.
With Snowpark, developers and data scientists can work in familiar languages like Python or Scala and still run that logic within Snowflake—ideal for advanced use cases like machine learning or complex text processing.
Building trust with governance and visibility
Security and governance are essential parts of any data pipeline. Snowflake includes fine-grained access controls, dynamic masking, and row-level policies to protect sensitive data. Object tagging and the information schema help you track data lineage, understand how data has changed, and meet compliance requirements. If you’re using a cataloging solution like Coalesce Catalog, you can also surface this metadata to make it easier for teams to trust and reuse transformed data.
Mastering these concepts—schema layering, SQL-based transformation, orchestration, and governance—lays the foundation for high-quality Snowflake data transformation. Up next, we’ll walk through best practices for putting these into action.
Data transformation best practices in Snowflake
Once you understand the basics, it’s time to focus on what makes Snowflake transformation pipelines reliable, scalable, and efficient. These best practices cover how to set up your workflows, manage resources, and build processes that are easier to maintain and grow.
1. Start with ELT to simplify your workflow
In Snowflake, the ELT (Extract, Load, Transform) method works best. Why? Because it turns the warehouse into a transformation engine—maximizing performance, reducing data movement, and aligning with scalable, cost-effective cloud principles.
First, bring raw data into Snowflake. Then, transform it directly within the platform. This approach avoids extra data movement and takes full advantage of Snowflake’s processing power. It also simplifies your stack—you don’t need a separate transformation solution to handle the heavy lifting.
2. Break your pipeline into layers
Use a layered approach to manage complexity. Organize your data into four key layers: raw, staging, intermediary, and marts.
- Raw tables store incoming data exactly as it arrives.
- Staging tables clean, standardize, and format the data into consistent schemas.
- An intermediary layer serves as a transformation layer that joins, enriches, and reshapes data across domains—providing a reusable foundation for multiple downstream use cases.
- Curated marts are optimized for reporting, dashboards, or machine learning.
This layered architecture improves traceability, simplifies debugging, and promotes reuse of logic across teams.
3. Be smart about compute usage
Snowflake’s compute resources—virtual warehouses—are billed by size and usage time, so it’s important to tune them thoughtfully. Use auto-suspend and auto-resume to avoid paying for idle compute, and monitor your credit consumption regularly. Some workloads benefit from larger warehouses to improve speed and throughput, while others may run efficiently on smaller configurations—it depends on the job.
It’s also a good practice to separate workloads across different warehouses, not just for performance isolation, but for cost transparency—making it easier to see how long each workload runs and how much it costs per tool or team. To dive deeper into tuning performance and cost, check out our article on optimizing your SQL workloads.
4. Use incremental updates with Streams and Tasks
Don’t reprocess all your data every time. Snowflake Streams track changes like new or updated rows. Tasks let you process those changes on a schedule or in real time. For example, you can build a task that updates your sales report every hour using only the new data. This reduces compute time and speeds up delivery. If your pipeline has several steps, you can chain tasks so each one runs in the right order.
5. Write SQL that scales
When writing SQL for transformations, aim for clean and efficient code.
- Use joins, filters, and aggregations on sets of data rather than row-by-row operations.
- Break long queries into smaller logical steps that can be quickly understood.
- Avoid unnecessary joins, and filter your data early to reduce processing time.
- Use the Query Profile tool to spot slow queries or bottlenecks, and test your code on sample data before rolling it out to full datasets.
6. Build governance into your workflow
Good governance starts early. These practices help build trust in your data and make it easier to audit or troubleshoot your pipelines.
- Use role-based permissions and masking policies to protect sensitive data.
- Tag important tables or columns so you can track how data flows through your system.
- Keep records of what each transformation does, and use tools like Coalesce Catalog to make lineage visible across your team.
7. Treat your SQL like production code
Think of your SQL as software. Store your scripts and configs in version control, document them clearly, and write reusable code wherever possible. Platforms like Coalesce help you document, test, and organize your transformations so others can jump in and understand what’s happening. This reduces errors and speeds up onboarding for new team members.
8. Monitor and improve continuously
Your pipeline isn’t “done” once it runs—keep improving it. Optimization is an ongoing habit, not a one-time task.
- Set alerts to catch failures or slowdowns.
- Use query history and warehouse stats to identify inefficient jobs.
- Stay up to date with new features in Snowflake, like Dynamic Tables or Snowpark, that might streamline your workflows.
By following these practices—keeping transformations in Snowflake, layering your architecture, optimizing compute use, using Streams and Tasks, embedding governance, and writing maintainable SQL—you’ll build pipelines that deliver faster and are easier to scale and maintain.
Emerging trends in data transformation in 2025
As more companies modernize their data platforms, several key trends are changing how teams work with Snowflake in 2025. These shifts reflect broader changes in how businesses think about data ownership, speed, AI integration, and pipeline reliability. Staying on top of these trends can help you build a more resilient and forward-looking transformation strategy.
Giving teams control with data mesh
Traditionally, a central data team handled all transformation logic. But in large companies, that model doesn’t scale. Data mesh is an approach that gives ownership to different departments—like finance, marketing, or product—so they can manage and share their own datasets. With Snowflake, it’s possible to support this model using features like cross-database queries, secure sharing, and granular access control. Instead of waiting on a central team, business units can build and maintain their own transformations.
AI is making transformation easier and faster
AI tools are becoming everyday helpers for data teams. They can suggest SQL queries, find slow parts of your pipeline, or flag unusual data before it causes issues. In Snowflake, new features like Cortex AI and Snowpark ML make it possible to train and run machine learning models directly in the platform. Teams can use these tools to automate repetitive tasks or run predictive models in real time. AI copilots, like Coalesce Copilot and GitHub Copilot, are also helping engineers transform data efficiently, generate code faster, and catch mistakes earlier.
From batch to real time: continuous data pipelines
Gone are the days of once-a-day data refreshes. More teams now expect their data pipelines to update in near real time. With tools like Snowpipe, Streams, Tasks, and Dynamic Tables, Snowflake can support continuous updates. That means dashboards, alerts, and applications can react to new data as it arrives—whether it’s a website click or a point-of-sale transaction. But to support this kind of speed, pipelines must be designed carefully from the start to handle streaming loads and ensure data accuracy.
Making pipelines more visible and accountable
As pipelines grow, so does the need to monitor them. In 2025, teams should be treating data workflows like software: versioned, tested, and observable. Tools for data observability (such as Monte Carlo) now track data quality, lineage, and uptime in real time. Snowflake helps with this through features like Access History, object tagging, and metadata queries. This makes it easier to answer questions like “Where did this data come from?” or “Why did this number change?”, which are critical for audits, compliance, and decision-making.
Bridging the gap between data engineering, analytics, and ML
The lines between data engineering, business intelligence (BI), and machine learning are blurring. One dataset might serve a dashboard, feed a model, and drive a real-time alert. Snowflake supports this convergence with integrations like Streamlit (for building apps) and Native Apps (for productizing data). As more teams use the same data for multiple purposes, pipelines need to be more flexible and documented so that different stakeholders—from analysts to data scientists—can work together efficiently.
These emerging trends—distributed data ownership, AI-powered development, real-time pipelines, observability, and cross-functional collaboration—are reshaping what data transformation in Snowflake looks like. In the final section, we’ll explore how Coalesce helps teams meet these challenges with a platform built for speed, scale, and governance.
Coalesce for Snowflake data transformation
While Snowflake offers powerful transformation capabilities, many organizations look to complement it with tools that simplify development, enhance governance, and accelerate delivery. Coalesce is a Snowflake-native transformation and governance platform that delivers all of this—without compromising flexibility or performance.
Built for Snowflake
Coalesce was built from the ground up to integrate deeply with Snowflake. It generates Snowflake-native SQL behind the scenes, ensuring full compatibility and optimal performance. There’s no proprietary execution layer—everything runs directly in your Snowflake environment. Snowflake Ventures has even invested in Coalesce, a testament to its alignment with the platform’s vision.
Get started quickly with Snowflake integration
If you’re new to Coalesce, the Snowflake Quickstart guide is a great place to begin. It walks you through connecting your Snowflake account, configuring storage, and building node graphs to transform your data—all with step-by-step videos and hands-on examples.
Build pipelines faster using reusable components
With Coalesce, you define transformation logic using reusable Node Types and visual workflows. This lets teams templatize common operations—like Type 2 Slowly Changing Dimensions or standard aggregations (like AVG, COUNT, MAX, MIN, and SUM)—and apply them consistently.
Guides such as our Foundational Hands-On Guide and Using Coalesce Marketplace show how to create and share these building blocks across teams, dramatically speeding up development and reducing error rates.
Modernize complex logic with pipeline-based development
Stored procedures have traditionally been used to manage complex SQL logic, but they can quickly become opaque and difficult to maintain at scale. Coalesce offers a more transparent, modular alternative: pipeline-based development that breaks logic into manageable, reusable components.
Instead of relying on monolithic stored procedures, you can recreate and orchestrate that logic in Coalesce using intuitive node-based workflows—with built-in lineage, versioning, and parameterization. This makes it easier to troubleshoot, scale, and collaborate across teams. Learn more about migrating from stored procedures to Coalesce.
Operationalize AI and ML with Snowflake Cortex
Coalesce supports the integration of AI and ML directly into your transformation pipelines. For example, you can use Snowflake Cortex functions to classify text or forecast values without writing any code. Our guide on Operationalizing ML with Snowflake Cortex walks you through embedding these capabilities into production pipelines.

Use advanced table formats like Iceberg
As more companies adopt lakehouse architectures, Coalesce has added support for open table formats like Apache Iceberg. Learn how to use Iceberg in combination with Cortex in our guide on Building Pipelines with Iceberg and Cortex and the follow-up on LLM-based transformations.
Simplify real-time orchestration with Dynamic Tables
Coalesce makes it easy to build and manage Dynamic Tables in Snowflake—a feature that automates data refreshes and supports real-time use cases. These tables reduce manual orchestration and keep your data current without the complexity of managing schedules.
Conclusion
The combination of Snowflake and Coalesce empowers data teams to move faster, govern with confidence, and build pipelines that scale. Coalesce takes what’s possible in Snowflake and streamlines it—offering reusable templates, rich documentation, column-level lineage, and a guided interface that supports even the most advanced transformation scenarios.
Whether you’re modernizing legacy ETL workflows or designing new real-time analytics, Coalesce helps you get more from your Snowflake investment—while building a foundation that’s future-ready.
To explore the full list of technical resources and step-by-step product walkthroughs, visit the Coalesce Guides Library.
Start transforming Snowflake data with Coalesce
Build on the only developer platform that’s purpose-built for Snowflake ETL/ELT. Simplify how you discover, transform, and govern your data to deliver projects faster, reduce risk, and get more out of every Snowflake credit.