Databricks SQL has emerged as a powerful lakehouse-native data warehouse, trusted by over 11,000 customers worldwide for their analytics workloads. Built on the Data Intelligence Platform, it promises to unify the entire data lifecycle—from ingestion to insights—with AI-powered capabilities, serverless scalability, and seamless integration with business intelligence tools. For data engineers and architects working with Databricks, the platform represents a significant step forward in combining the flexibility of data lakes with the performance and governance of traditional data warehouses.
However, as organizations adopt Databricks SQL and scale their lakehouse implementations, one critical challenge continues to demand attention: data transformation complexity.
Key Insight
The “T” in ELT remains the most complex, time-consuming, and maintenance-heavy part of the data pipeline. While Databricks SQL excels at query performance with its Photon engine and integrates seamlessly with BI tools, the transformation layer often becomes a bottleneck that slows teams down, introduces technical debt, and creates scalability challenges as data estates grow.
This comprehensive guide explores the landscape of data transformation in Databricks SQL, examining the available native approaches, common challenges that affect teams of all sizes, and industry best practices for building maintainable lakehouse pipelines. More importantly, it reveals how modern transformation platforms like Coalesce can help teams build faster, scale more efficiently, and maintain data quality without the typical overhead that plagues manual development approaches.
What you’ll learn in this guide:
- The transformation capabilities available within Databricks SQL and when to use each approach
- Core challenges that slow down data engineering teams and introduce technical debt
- Proven best practices for lakehouse data transformation and the medallion architecture
- How purpose-built transformation platforms dramatically accelerate Databricks SQL development cycles while maintaining governance and quality standards
Whether you’re evaluating Databricks SQL, currently implementing transformation pipelines, or looking to optimize existing workflows, this guide provides the technical insights and practical strategies you need to succeed.
Understanding Databricks SQL’s data transformation ecosystem
Databricks SQL operates as a key component of the Databricks Data Intelligence Platform, built on lakehouse architecture that combines the cost-effectiveness and scalability of data lakes with the performance and governance capabilities of data warehouses. At its foundation sits Delta Lake, an open-source storage framework that provides ACID transactions, schema enforcement, and time travel capabilities. Unity Catalog serves as the unified governance layer, managing metadata, access controls, and lineage across all data assets.
For data engineers focused on transformation, Databricks provides multiple native approaches, each with distinct strengths and appropriate use cases. Understanding these options helps teams make informed architectural decisions and recognize where each approach excels—and where challenges emerge at scale.
Core transformation capabilities
Databricks SQL Editor and Queries
The Databricks SQL editor, now generally available with extensive enhancements in 2025, provides a collaborative SQL development environment for building transformations. It supports complex SQL transformations, materialized views for performance optimization, and streaming tables for continuous data ingestion. Recent updates include real-time collaboration features, inline execution history, and enhanced Databricks Assistant integration for AI-powered SQL generation.
Strengths: Data engineers familiar with SQL can leverage this interface immediately without learning new frameworks. The editor provides strong support for structured data transformations and integrates naturally with BI tools.
Limitations: Building complex transformation pipelines requires manual development of each object, careful dependency management, and significant effort to maintain consistency across hundreds of tables. While the SQL editor handles individual transformations well, scaling to enterprise data warehouses with interconnected pipelines reveals coordination challenges.
Notebooks for Programmatic Transformations
For transformations requiring custom business logic or complex processing, Databricks notebooks provide full programmatic control through PySpark, Scala, and SQL. The notebooks integrate with Databricks Runtime, which includes performance optimizations beyond open-source Apache Spark, and support collaborative development with versioning capabilities.
Strengths: Maximum flexibility for implementing sophisticated transformation patterns, handling complex data types, and processing large-scale datasets with Spark’s distributed computing capabilities.
Challenges: Each transformation requires custom code development, creating maintenance burdens as pipelines grow. Teams often struggle with code duplication across notebooks, inconsistent patterns between different engineers, and limited visibility into transformation dependencies. The power of programmatic control comes with the responsibility of ensuring standardization manually.
Delta Live Tables (DLT)
Delta Live Tables provides a declarative framework specifically designed for building reliable data pipelines on Databricks. DLT manages dependency resolution automatically, provides built-in data quality expectations, and supports the medallion architecture pattern natively. The framework handles orchestration internally, eliminating the need to manually coordinate transformation execution order.
Strengths: Simplified pipeline management compared to manual orchestration, automatic dependency tracking, and integrated data quality validation. DLT is particularly strong for teams adopting the medallion architecture and seeking to reduce boilerplate code.
Challenges: Learning curve for teams accustomed to procedural programming approaches, limited customization for edge cases requiring specialized logic, and complexity that can be intimidating for business analysts or less technical team members. While DLT reduces certain types of complexity, it introduces its own abstractions that require understanding.
Workflows for Orchestration
Databricks Workflows provides the orchestration layer, coordinating execution across notebooks, SQL queries, Delta Live Tables pipelines, and external systems. It includes scheduling, monitoring, and alerting capabilities integrated into the Databricks platform.
Strengths: Native orchestration eliminating the need for external tools, integrated monitoring showing job performance and data lineage, and straightforward scheduling for batch processing patterns.
Limitations: Workflows handle execution coordination but don’t reduce the manual effort required to develop the underlying transformation logic. Teams still need to build, test, and maintain each individual transformation component.
| Transformation Approach | Best For | Key Strengths | Primary Limitations |
|---|---|---|---|
| SQL Editor & Queries | Structured data transformations | Familiar SQL interface, BI integration | Manual development, dependency management |
| Notebooks (PySpark/Scala) | Complex programmatic logic | Maximum flexibility, distributed processing | Code duplication, maintenance burden |
| Delta Live Tables | Declarative pipelines | Automatic dependencies, built-in quality | Learning curve, limited customization |
| Workflows | Multi-task orchestration | Integrated monitoring, native to platform | Doesn’t reduce transformation development effort |
For a comprehensive overview of Databricks SQL capabilities beyond transformation, see the official Databricks SQL documentation.
The core challenges of data transformation in Databricks SQL
Despite Databricks SQL’s powerful capabilities and continuous improvements, data engineering teams consistently encounter several pain points when building and maintaining transformation pipelines at scale. These challenges affect organizations of all sizes, though they become particularly acute as data estates grow beyond initial proof-of-concept implementations.
Development velocity constraints
Manual coding overhead
Every transformation in Databricks SQL—whether built with SQL queries, PySpark notebooks, or Delta Live Tables—requires hands-on development. Data engineers must write specifications, define logic, configure dependencies, and test each component individually. For a typical enterprise data warehouse containing hundreds of tables and thousands of transformation steps, this manual approach creates significant time investment.
The impact is measurable: development cycles for complex projects often stretch to months. When business requirements change or new data sources need integration, the response time reflects the inherent bottleneck of building everything from scratch. Teams find themselves perpetually behind, unable to deliver analytics capabilities at the speed business stakeholders expect.
Slow iteration cycles
The nature of transformation development in Databricks SQL requires full execution to validate logic. Testing a hypothesis about business rules or data quality checks means running the transformation pipeline, examining results, adjusting code, and running again. This cycle consumes significant compute resources and developer time.
The challenge intensifies during the exploration phase when business stakeholders aren’t entirely certain of requirements. The natural way of working—building prototypes, examining data patterns, iterating based on findings—becomes tedious when each iteration requires manual code changes and full pipeline execution. This friction discourages experimentation and often results in transformations that work but aren’t optimal because further refinement would be too time-consuming.
Technical debt accumulation
Inconsistent development patterns
Without enforced standards, different engineers inevitably implement transformation logic differently. Senior engineers may write concise, optimized SQL while junior team members take more verbose approaches. Some developers prefer CTEs (common table expressions) while others chain views. SCD Type 2 logic gets implemented multiple ways across different dimension tables.
This inconsistency creates several problems. Code reviews become more difficult when each transformation follows different patterns. Maintenance requires understanding various coding styles. New team members must learn multiple approaches rather than one standardized method. When bugs appear, similar issues may exist in transformations written with different patterns, requiring separate fixes rather than a single solution.
Maintenance complexity
As transformation logic scatters across SQL queries, notebooks, DLT pipelines, and stored procedures, maintenance becomes exponentially more difficult. A business rule change that should take hours to implement instead requires hunting through multiple objects to find every place the logic appears. Code duplication means the same transformation logic might exist in three different notebooks, and all three need updates.
Organizations often discover that undocumented business rules are buried deep in code, known only to the engineer who wrote them. When that engineer leaves or moves to another project, the tribal knowledge vanishes. Onboarding new team members becomes challenging—they must reverse-engineer transformation logic from code rather than consulting clear documentation that explains the business context and reasoning behind implementation decisions.
Warning: Technical debt in transformation pipelines compounds over time. Today’s quick solution becomes tomorrow’s maintenance nightmare, and the cost of addressing accumulated debt grows exponentially as more transformations build on inconsistent foundations.
⚠️ Warning: Technical Debt Compounds Over Time
Technical debt in transformation pipelines compounds over time. Today’s quick solution becomes tomorrow’s maintenance nightmare, and the cost of addressing accumulated debt grows exponentially as more transformations build on inconsistent foundations.
Limited visibility and impact analysis
Dependency management challenges
Understanding how data flows through transformation pipelines remains one of the most difficult aspects of working with Databricks SQL at scale. Data engineers need to answer fundamental questions: “If I change this source column, what downstream transformations will break?” or “Which dashboards depend on this table?” Without comprehensive lineage, these questions require manual investigation—tracing through code, checking dependencies, and hoping nothing was missed.
Unity Catalog provides table-level lineage, showing which tables feed into others. However, column-level lineage—understanding how individual fields transform and flow through the pipeline—requires additional tooling or manual documentation. This gap creates anxiety around changes. Teams implement elaborate manual review processes to validate modifications, slowing deployment cycles from days to weeks or even months.
The impact on productivity is substantial. Changes that should take hours require extensive validation work. Teams become risk-averse, avoiding improvements that would benefit the business because the effort to validate impact seems prohibitive. The result is stagnation—transformation pipelines that work but never get optimized or modernized because change is too expensive.
Standardization and governance gaps
Pattern proliferation
As Databricks environments grow, maintaining standards becomes increasingly difficult without enforced templates or patterns. Each team develops their own approaches to transformation logic. Naming conventions vary across projects—one team uses fact_ prefixes while another uses fct_. Documentation practices differ, with some teams maintaining comprehensive metadata and others documenting nothing at all.
Security and compliance requirements become challenging to enforce uniformly. Does every transformation properly filter sensitive data? Are all PII columns masked according to policy? Without standardized approaches and automated checks, governance becomes “governance by hope”—hoping teams follow standards rather than enforcing them systematically.
The drift that occurs naturally as teams scale creates long-term problems. Audit and compliance become complicated when there’s no consistent approach. Knowledge silos form as each team’s custom patterns become understood only by that team. Cross-team collaboration suffers because transformations built by different teams follow completely different paradigms.
Scalability and collaboration barriers
Individual object management
Approaches that work well at small scale break down as transformation counts grow. Managing 10-50 transformations manually is feasible. Coordinating hundreds or thousands of transformation objects becomes prohibitive. Manual effort to modify patterns across many objects consumes weeks. Applying consistent changes—updating a common join pattern or implementing new quality checks—requires touching numerous individual transformations.
Multi-catalog complexity adds another dimension. Organizations often maintain separate catalogs for different business domains, regions, or data stages. Managing transformations across multiple catalogs, ensuring cross-environment consistency, and migrating changes between development, staging, and production environments all require careful coordination that manual processes struggle to support at scale.
High technical bar
Databricks SQL transformations require SQL or PySpark expertise. Business analysts who understand the data and business rules often struggle to contribute because they lack the technical skills to implement transformations. This creates bottlenecks on data engineering teams, which become order-takers translating business requirements into code rather than strategic partners focused on complex problems.
The result is limited self-service capabilities. Business stakeholders can’t explore questions themselves through iterative transformation development. Instead, they submit requests to data engineering, wait for implementation, review results, request changes, and repeat the cycle. The feedback loop is slow, discouraging the experimentation that leads to valuable insights.
Scalability Warning: What works for 50 transformations breaks at 500. Teams often don’t recognize the inflection point until they’re already struggling with scale. Plan for growth before manual processes become entrenched.
⚠️ Scalability Warning
What works for 50 transformations breaks at 500. Teams often don’t recognize the inflection point until they’re already struggling with scale. Plan for growth before manual processes become entrenched.
Best practices for data transformation in Databricks SQL
While the challenges are significant, data engineering teams can adopt proven practices to improve their Databricks SQL transformation workflows. These best practices reduce friction, improve maintainability, and create foundations for scaling data pipelines effectively.
Embrace the medallion architecture
The medallion architecture has become the standard pattern for organizing data in lakehouses, providing clear separation of concerns across the data pipeline. This approach divides data into three distinct layers, each with specific transformation responsibilities.
The Bronze layer serves as the raw data landing zone, implementing minimal transformation. Data arrives from source systems in its original format, with basic schema enforcement and data type validation but without business logic. The bronze layer provides a reliable audit trail, capturing data exactly as it was received and enabling time travel to recover from errors or replay historical processing.
The Silver layer focuses on cleaning, validating, and standardizing data. Transformations here implement data quality checks, deduplicate records, standardize formats, and resolve data quality issues identified in the bronze layer. The silver layer represents “clean” data ready for business logic application, though not yet optimized for specific analytics use cases.
The Gold layer contains business-ready datasets optimized for analytics and reporting. Transformations at this level implement business logic, create aggregations, build dimension and fact tables following star or snowflake schemas, and optimize data structures for query performance. Gold layer tables directly support dashboards, reports, and ad-hoc analytics.
| Layer | Purpose | Transformation Level | Example Patterns |
|---|---|---|---|
| Bronze | Raw data landing | Minimal—load as-is from sources | Schema enforcement, timestamp addition |
| Silver | Cleaned & validated data | Data quality, standardization | Deduplication, format standardization, quality checks |
| Gold | Business-ready datasets | Business logic, aggregations | Star schema, KPI calculations, report optimization |
Benefits of this approach include clear separation that makes transformation logic easier to reason about and maintain, quality improvements that occur incrementally across layers rather than attempting everything in a single step, and natural support for data governance requirements by establishing checkpoints where quality can be validated. Teams can focus optimization efforts appropriately—bronze prioritizes data capture reliability, silver focuses on quality, gold optimizes for performance.
For detailed implementation guidance, see the Databricks medallion architecture documentation.
Leverage Delta Lake and optimization features
Delta Lake provides the foundation for reliable transformations in Databricks, offering capabilities that go beyond basic data storage. ACID transactions ensure transformation reliability, preventing partial updates and maintaining consistency even when multiple processes write to the same tables. This transaction support eliminates data corruption risks that plague systems without such guarantees.
Z-ordering reorganizes data within files based on frequently queried columns, dramatically improving query performance by reducing the amount of data scanned. For transformations that repeatedly filter on specific columns, Z-ordering can provide 3-10x query speed improvements. Liquid clustering, a newer feature, automatically optimizes data layout as write patterns evolve, eliminating the need for manual Z-order maintenance. It dynamically adapts to changing query patterns, providing performance benefits without ongoing manual tuning.
Optimize write improves file sizes during writes, creating fewer, larger files that are more efficient to read. Combined with other optimizations, this feature reduces storage costs through better compression while improving query performance. These optimization techniques work best when applied consistently across transformation pipelines. However, implementing them requires remembering to configure settings for each table—a task that becomes tedious across hundreds of transformations.
Implement incremental processing patterns
One of the most impactful optimizations for transformation performance is avoiding full table reloads. Processing only changed or new data reduces compute costs, decreases processing time, and enables more frequent refresh cycles.
Watermark columns—typically modified timestamps or sequence numbers—identify records that changed since the last processing cycle. Transformations query for records where the watermark exceeds the last processed value, bringing in only net-new or updated records. Change data capture (CDC) patterns go further, capturing insert, update, and delete operations from source systems and applying those changes efficiently to target tables. Delta Lake’s merge operation handles upserts elegantly, combining inserts and updates in a single statement.
Materialized views with auto-refresh capabilities provide a powerful tool for maintaining fresh aggregations without manual orchestration. The system tracks source table changes and refreshes the materialized view automatically, ensuring analytical queries always see current data without expensive full recalculations. Streaming tables enable continuous ingestion for use cases requiring real-time or near-real-time data. Rather than batch processing every few hours, streaming tables process records as they arrive, maintaining minimal latency between source systems and analytics.
The performance impact of incremental processing grows with data volumes. A transformation processing gigabytes might see 90%+ reduction in processing time compared to full reloads. For terabyte-scale datasets, incremental processing often means the difference between feasible and infeasible transformation approaches.
Establish standards and quality checks
Consistent standards become exponentially more important as data estates scale. Without them, the inconsistencies discussed earlier proliferate until maintenance becomes overwhelming.
Establish and enforce naming patterns for catalogs, schemas, tables, and columns. For example: catalogs named by data domain (finance_data, customer_data), schemas named by layer and source (bronze_salesforce, silver_crm, gold_analytics), tables prefixed by type (fact_orders, dim_customer, agg_daily_sales), and columns following consistent patterns (customer_id, order_date, total_amount_usd).
The critical insight: these standards must be enforced, not just documented. Documentation that isn’t followed provides no value. Manual enforcement fails as teams scale. The solution requires either automated validation that rejects non-compliant objects or tooling that makes it easier to follow standards than to violate them.
Building quality checks into transformations prevents bad data from propagating downstream. Different quality check types apply at different stages:
| Check Type | Examples | When to Apply |
|---|---|---|
| Completeness | Null checks, required field validation | Bronze → Silver |
| Accuracy | Data type validation, range checks, format validation | Silver layer |
| Consistency | Referential integrity, cross-table validation | Silver → Gold |
| Timeliness | Freshness checks, latency monitoring | All layers |
| Uniqueness | Duplicate detection, primary key validation | Silver layer |
Delta Live Tables provides expectations for declarative quality checks, but implementing comprehensive quality frameworks requires significant upfront investment. Teams must decide which checks to implement, write the validation logic, establish thresholds for failures versus warnings, and maintain the quality framework as business rules evolve.
Version control and CI/CD practices
Treating transformation code like application code improves change management and reduces deployment risks. Databricks now provides Git support for queries (a 2025 feature), enabling version control for SQL transformations. Databricks Git folders support notebooks, providing version control for PySpark and Scala code. These capabilities enable proper change tracking, code review processes, and rollback capabilities when issues arise.
However, Git integration requires discipline. Teams must establish branching strategies, enforce code review before production deployment, and maintain consistency across different artifact types. The setup and ongoing management add overhead that smaller teams sometimes struggle to justify.
CI/CD pipelines automate testing and deployment, reducing manual errors and enabling more frequent releases. Automated validation catches issues before they reach production. Environment promotion (development → staging → production) becomes systematic rather than ad-hoc. The challenge: building robust CI/CD requires significant setup and continuous maintenance. Teams must write test scripts, configure pipelines, handle secrets and credentials securely, and adapt automation as transformation patterns evolve.
How Coalesce accelerates Databricks SQL data transformations
Coalesce brings transformational efficiency to Databricks SQL by addressing the core challenges that slow down data engineering teams. Rather than replacing Databricks, Coalesce enhances it by providing a purpose-built transformation layer that automates pipeline development, generates optimized code for Databricks SQL, and offers a superior development experience that makes the best practices discussed earlier accessible to teams of all sizes.

The platform serves as a simplified command center for Databricks SQL projects—powerful and adaptable, with an approachable visual interface that doesn’t sacrifice the flexibility of code-first development.
Visual development with code generation
Traditional transformation development in Databricks SQL requires engineers to write every piece of logic manually. Coalesce transforms this paradigm through visual, column-aware development that maintains the power of code while dramatically accelerating the development process.
Coalesce provides a drag-and-drop transformation design interface where engineers can see data types, lineage, and dependencies at the column level. Rather than writing SQL queries blind, developers work with a visual representation showing exactly how data flows from sources through transformations to final outputs. This column awareness eliminates common errors—using the wrong data type, forgetting to handle nulls, or missing dependencies that will cause runtime failures.
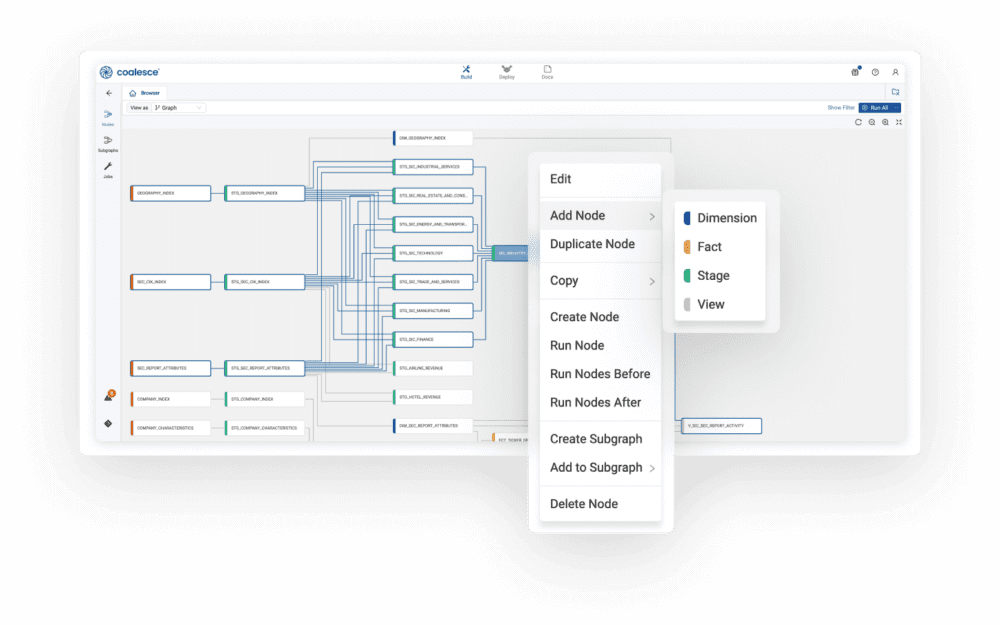
The visual interface doesn’t mean sacrificing precision or control. Engineers can see the generated SQL at any time, modify it when needed for special cases, and maintain full understanding of what’s being deployed to Databricks. The benefit is combining the speed of visual development with the power and flexibility of code-based approaches.
Once transformations are designed visually, Coalesce generates optimized Databricks SQL automatically. The generated code follows best practices—implementing proper error handling, using appropriate Delta Lake features, and following patterns that have been proven across thousands of implementations. Engineers don’t need to remember every syntax detail or configuration option; the platform ensures consistency automatically.
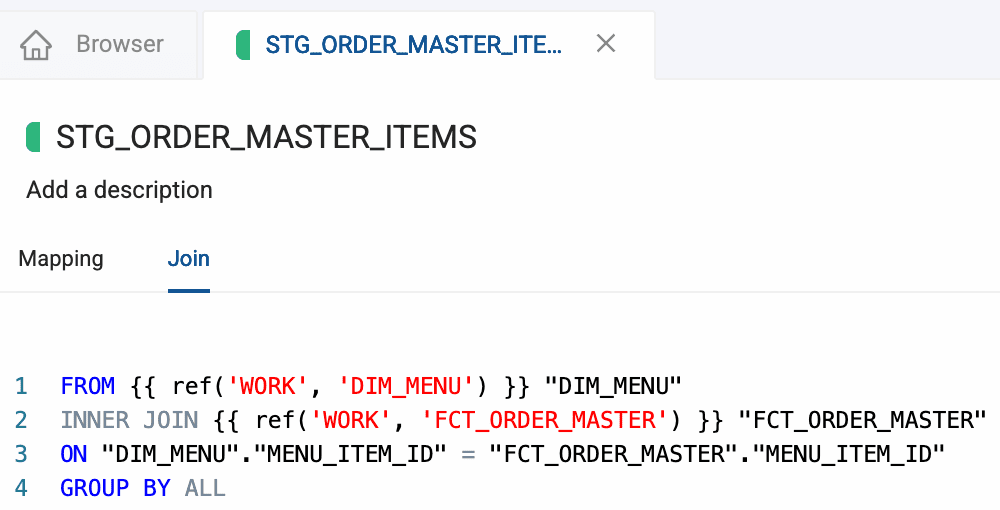
For the 90% of transformations that follow standard patterns, code generation means what previously took days to write, test, and debug now deploys in minutes. Engineers can focus their expertise on the 10% of transformations requiring custom logic rather than spending time on boilerplate code for routine patterns.
Consider a finance team building a customer health score pipeline. The requirement includes integrating multiple data sources (product usage, support tickets, billing), implementing complex scoring algorithms, and maintaining real-time dashboards. With native Databricks SQL tools, this project requires 4-6 weeks of development time, demanding SQL or PySpark expertise that the finance team doesn’t have.
Using Coalesce’s visual interface, the same finance team built 80% of the pipeline themselves, leveraging pre-built packages for common patterns and configuring business logic visually. The development time compressed to 1-2 weeks, and business stakeholders could contribute directly rather than waiting for data engineering resources. The impact: 10x faster development and business teams empowered to iterate on their own requirements.
Pre-built packages and marketplace
Reinventing common transformation patterns wastes time and introduces unnecessary risk. The Coalesce Marketplace provides pre-built packages containing proven implementations of standard patterns including:
✅ Lakeflow Declarative Pipelines – Declarative framework for Databricks pipelines
✅ Materialized Views – Auto-updating cached query results
✅ Data Vault by Scalefree for Databricks – Complete Data Vault implementation
✅ Base Node Types – Foundational fact and dimension construction
✅ Data Quality Package – Flexible data quality testing
✅ Incremental Loading – Purpose-built incremental loading nodes
✅ Test Utility – Great Expectations-inspired testing framework
These packages encapsulate best practices developed across customer implementations, tested extensively, and refined based on real-world usage. For Databricks specifically, marketplace packages implement optimized patterns that teams don’t need to research or develop from scratch.
When every team uses the same marketplace packages, standardization happens naturally rather than requiring enforcement. A slowly changing dimension works the same way regardless of which engineer implemented it or when it was created. This consistency eliminates the pattern proliferation problem discussed earlier, where each team invents their own approach to common patterns.
Development work becomes consumable, standardized, and reusable across the organization. New team members can understand transformations built by others because they follow familiar patterns. Maintenance becomes straightforward because similar transformations work similarly. Troubleshooting is easier because the behavior is predictable.
The time savings are substantial: patterns that would require days of development, testing, and debugging with manual code deploy in minutes with marketplace packages. Teams can focus their valuable engineering time on unique business logic rather than implementing infrastructure patterns that have been solved thousands of times already.
Column-level lineage and impact analysis
Understanding transformation dependencies transforms from a time-consuming manual investigation into an instant query. Coalesce automatically generates lineage documentation at the column level, showing exactly how each field flows from source to destination. Engineers can trace any column backward to see where it originated and what transformations were applied. Looking forward, they can see every downstream object that depends on a particular column.
This granularity matters enormously for impact analysis. Changing a source column type? The lineage shows immediately which transformations will be affected. Renaming a field? The platform identifies every downstream dependency that needs updating. Adding a new quality check? See exactly which gold layer tables will be impacted.
The comprehensive lineage enables a breakthrough in change management: validating impact in seconds rather than days or weeks. The elaborate manual review processes that slow deployment cycles become unnecessary. Engineers can confidently make modifications knowing exactly what will be affected and having validated that the changes won’t break downstream systems.
This capability represents effective data project management at scale. As transformation counts grow into hundreds or thousands, maintaining visibility becomes impossible without automation. Coalesce provides that automation, ensuring teams can continue moving quickly even as their data estates expand.
The platform also addresses the documentation problem: Coalesce automatically documents data projects in real time. As transformations are developed or modified, the documentation updates immediately. The data dictionary stays current automatically, column-level descriptions remain accurate, and the metadata integrates with Unity Catalog for enterprise-wide visibility.
Built-in governance and team collaboration
Governance becomes governance by design rather than governance by hope. Reusable node types in Coalesce enforce organizational patterns automatically. When engineers create a dimension table, they use a dimension node type that includes all required governance elements—data quality checks, audit columns, security classifications, and documentation templates. Consistency emerges regardless of who builds transformations or when they’re created.
Automatic documentation generation ensures every transformation includes descriptions explaining business logic and technical implementation. Security and compliance rules apply at design time, preventing non-compliant transformations from being created rather than catching violations after deployment.
Organizations working across multiple Databricks catalogs face coordination challenges. Coalesce manages transformations across the entire Databricks instance, whether using one catalog or dozens. Consistent patterns apply across all environments, eliminating the drift that occurs when each catalog is managed separately.
Data experts of all skill sets can collaborate through Coalesce’s universally accessible development experience. Senior data engineers leverage the platform’s power and flexibility. Business analysts contribute using the visual interface without writing code. All work happens in a coordinated, properly governed manner that’s easy to troubleshoot when issues arise.
This democratization doesn’t mean sacrificing quality. The governance framework ensures contributions from all team members follow standards. Rather than creating bottlenecks where only senior engineers can work on transformations, organizations unlock productivity across their entire data team.
Multi-engine architecture and version control
Modern enterprises rarely standardize on a single data platform. Organizations often use Databricks for lakehouse analytics, Snowflake for certain workloads, Microsoft Fabric for specific use cases, or other platforms based on acquisition history or specific requirements.
Coalesce provides a single development interface supporting multiple data platforms—Databricks, Snowflake, Microsoft Fabric, BigQuery, and Redshift. This multi-engine architecture enables teams to interact with any data platform through a consistent development experience, building transformations once and deploying them to the appropriate target.
For organizations running multi-cloud or multi-platform strategies, this flexibility prevents vendor lock-in. Transformations aren’t written in platform-specific code that would require complete rewrites if architecture decisions change. Instead, the business logic is captured in Coalesce’s platform-agnostic layer, with optimized code generated for the target platform automatically.
While this multi-platform capability isn’t the primary value proposition for teams exclusively on Databricks, it provides insurance against future architectural changes and supports enterprises with diverse data ecosystems.
All transformation definitions in Coalesce store in Git automatically, providing proper version control for all logic. Teams can implement branching strategies appropriate for their development workflows—feature branches for new development, release branches for staging deployments, hotfix branches for urgent production changes.
Code review processes happen naturally before production deployment, with reviewers able to see exactly what changed and understand the business impact. Rollback capabilities enable quick recovery when issues occur—revert to the previous version rather than frantically trying to remember what changed and manually fixing problems.
CI/CD pipelines integrate with Coalesce, automating validation before deployment and promoting changes through environments systematically. The audit trail captures all changes, supporting compliance requirements and troubleshooting efforts. Unlike native Databricks approaches that require custom solutions for comprehensive version control, Coalesce provides these capabilities out of the box.
Accelerated time to value
The productivity gains from Coalesce aren’t theoretical—they’re measurable and substantial. Organizations implementing Coalesce for Databricks SQL transformations typically report:
- 10x faster development cycles: What previously took months now takes weeks or days. The combination of visual development, code generation, and pre-built packages eliminates the tedious manual work that consumes time in traditional approaches.
- 80% reduction in maintenance time: Standardization and reusability reduce the ongoing support burden. When patterns need updates, the changes propagate automatically rather than requiring manual modifications to hundreds of individual transformations.
- 50% fewer production incidents: Column-level lineage and impact analysis prevent breaking changes from reaching production. Quality checks built into marketplace packages catch issues earlier in the development cycle.
- 90% faster onboarding: New team members become productive in days rather than months. The visual interface and standardized patterns are easier to learn than platform-specific code, and comprehensive documentation generated automatically provides context that would otherwise require tribal knowledge.
For data pipeline development and velocity—a primary use case—Coalesce enables teams to build adaptable, manageable, and reliable data pipelines without becoming Databricks experts. Data teams work efficiently to own and manage portions of pipelines in a concerted, standardized manner. This velocity is crucial for organizations that need to respond quickly to changing business requirements, onboard new data sources rapidly, or support agile analytics initiatives.
For AI/ML foundations—another primary use case—creating an enterprise data foundation for building, deploying, and governing AI/ML solutions requires high-quality, well-documented, consistently structured data. Coalesce enhances developer efficiency for these critical initiatives and helps data teams stay nimble as AI/ML requirements evolve. The governance framework ensures AI models train on trustworthy data, and the accelerated development cycles mean data teams can keep pace with rapidly changing ML requirements.
The platform also supports data mesh implementations by providing a simplified, visual, and standardized way of democratizing data ownership while ensuring that data products are well-managed and governed. Domain teams can build their own data products following organizational standards without creating chaos. For enterprises using multiple data platforms, the multi-engine architecture provides the ability to interact with Databricks, Snowflake, Fabric, BigQuery, and Redshift through a consistent development experience.
📊 Measured ROI
- 10x faster development cycles: Months → weeks or days
- 80% reduction in maintenance: Changes propagate automatically
- 50% fewer production incidents: Quality checks catch issues early
- 90% faster onboarding: Days instead of months for new team members
| Capability | Native Databricks SQL | Coalesce + Databricks |
|---|---|---|
| **Development Speed** | Manual coding/configuration for each transformation | Visual development with automatic code generation |
| **Standardization** | Manual enforcement through documentation | Built-in templates and node types enforcing patterns |
| **Impact Analysis** | Manual investigation or limited table-level lineage | Automatic column-level lineage with instant dependency tracking |
| **Reusability** | Copy/paste code with customization | Pre-built marketplace packages with proven patterns |
| **Version Control** | Complex custom setup required | Built-in Git integration for all transformation definitions |
| **Collaboration** | Requires SQL/PySpark expertise | Visual interface accessible to business analysts |
| **Multi-Platform** | Databricks-specific code | Works across Databricks, Snowflake, Fabric, BigQuery, Redshift |
| **AI Assistance** | Databricks Assistant for SQL generation | Coalesce Copilot for AI-powered transformation workflows |
| **Time to Value** | Months for complex projects | Weeks or days with accelerated development |
Explore Coalesce customer stories to see real-world results from teams using the platform with Databricks and other data platforms.
Real-world transformation scenarios
Understanding how these concepts apply in practice illuminates the value of optimized transformation approaches for Databricks SQL projects.
Scenario 1: Customer health score pipeline
A finance team needed real-time customer health monitoring, integrating multiple data sources including product usage metrics, support ticket history, and billing information. The requirement included complex scoring algorithms and dashboard integration with real-time updates—all needed quickly for an upcoming executive presentation.
The traditional path with native Databricks SQL tools would involve writing custom SQL for each data source integration, implementing the scoring logic in notebooks or stored procedures, creating materialized views for dashboard performance, and building orchestration with Workflows. Extensive testing and validation would be required to ensure accuracy. Estimated development time: 4-6 weeks, assuming data engineering resources were available immediately.
Using Coalesce’s visual interface, the finance team defined data sources and configured transformation logic through drag-and-drop. Pre-built packages handled common patterns like data quality validation and incremental loads. The automatic refresh orchestration eliminated the need to configure Workflows manually. Built-in data quality checks provided confidence without extensive manual testing.
The project compressed to 1-2 weeks of development time. Critically, the finance team built 80% of the pipeline themselves using Coalesce’s approachable interface, without requiring extensive data engineering expertise. The 10x faster development enabled the team to iterate multiple times based on early results, ultimately delivering a more sophisticated solution than originally scoped. Business stakeholders could contribute directly to transformation development, fundamentally changing the team’s ability to respond to analytical requirements.
Scenario 2: Enterprise data warehouse migration
Migrating 500+ transformation objects from a legacy data warehouse system to Databricks SQL while preserving business logic, maintaining data quality standards, and minimizing disruption to existing reports and analytics presents significant challenges.
The native approach requires manually rewriting each transformation to Databricks SQL or PySpark, translating legacy code patterns to modern equivalents, extensive testing to ensure logic preservation, and careful coordination of the migration sequence. The high risk of logic errors during translation creates anxiety. With traditional manual development, the team becomes the bottleneck, with estimated timeline: 9-12 months.
The visual interface in Coalesce makes legacy logic easier to understand by representing transformations graphically rather than requiring code interpretation. The standardized approach reduces errors by ensuring all transformations follow proven patterns rather than requiring custom implementation decisions. Accelerated testing through automatic lineage enables quick validation of migration results. Team productivity multiplies through reusable patterns—once one dimension migration is perfected, the pattern applies to all dimensions.
Coalesce Copilot, the AI-powered assistant integrated into the platform, provides intelligent suggestions for transformation patterns, helps document business logic automatically, and accelerates common development tasks. This AI assistance is particularly valuable during migrations when teams need to understand legacy logic quickly and implement modern equivalents efficiently.
Estimated time with Coalesce: 3-4 months. The impact includes faster migration timeline, significantly lower risk of business logic errors, and a modernized transformation environment that’s more maintainable than the legacy system or a direct code translation would have been.
Scenario 3: Data mesh implementation
Implementing federated data ownership across business domains while maintaining consistent data products, clear governance, and centralized quality standards requires careful balance. Each domain team needs transformation capabilities without creating chaos or compromising organizational governance.
The challenge lies in giving each domain transformation capabilities while maintaining standards. Visibility into cross-domain dependencies is essential to prevent one domain’s changes from breaking another domain’s data products. Quality assurance across teams typically requires dedicated governance resources that become bottlenecks.
Coalesce provides a simplified, visual, and standardized way of democratizing data ownership. Domain teams build transformations using consistent patterns enforced by the platform, eliminating the concern that different domains will work completely differently. Centralized governance functions without becoming a bottleneck because standards are enforced by the tool rather than requiring manual review.
Column-level lineage automatically tracks cross-domain dependencies, alerting teams when changes might impact other domains’ data products. Quality frameworks apply consistently across all domains through marketplace packages, ensuring that data products are well-managed and governed regardless of which domain team created them.
The result: data mesh benefits—domain ownership, faster response to business needs, scalable governance—without the chaos that often accompanies federated models. Each domain team moves quickly within guardrails that ensure organizational consistency.
Getting started with optimized Databricks SQL transformations
For teams looking to improve their Databricks SQL transformation workflows, a structured approach provides the clearest path to measurable improvement.
Assess current state and identify opportunities
Start by quantifying current transformation complexity. Count transformation objects across all catalogs—SQL queries, notebooks, DLT pipelines. Measure the time to implement typical changes, tracking how much time goes to new development versus maintaining existing transformations. Monitor deployment frequency and production incidents related to transformations. This baseline establishes the starting point for measuring improvement.
Identify opportunities for quick wins by finding patterns in current work. Look for similar logic implemented multiple times—are there five different versions of customer aggregations? Spot inconsistent approaches to common problems like slowly changing dimensions or incremental loads. Find copy/paste code that could be replaced with standardized templates. Document the undocumented standards that experienced team members follow but new team members don’t know about.
These opportunities represent low-hanging fruit. Addressing them through standardization and reusable components provides immediate productivity gains while building the foundation for larger improvements.
Implement column-level lineage and modern practices
Implementing column-level lineage transforms impact analysis. Rather than spending days investigating what might break, engineers see immediately which objects use each column. Breaking changes are identified before deployment rather than discovered in production. Transformation logic is documented automatically, reducing reliance on tribal knowledge. Confident, rapid changes become possible because the impact is known and validated.
The shift from weeks to hours for impact analysis isn’t hyperbole—it’s the measured experience of teams that implement comprehensive lineage. The return on investment is immediate and compounds over time as transformation counts grow.
Store all transformation logic in Git, implementing branching strategies appropriate for your development process. Require code review before production deployment to catch issues early and share knowledge across the team. Build reusable transformation pattern libraries, documenting best practices and making them easily accessible. Alternatively, leverage the Coalesce Marketplace for access to proven patterns without the investment of building and maintaining a custom library.
Evaluate transformation platforms
When evaluating purpose-built transformation platforms like Coalesce, start with a focused pilot project. Choose a subset of transformations representing realistic complexity—not the simplest transformations where any approach works, but also not the most complex edge cases. Measure the impact quantitatively: development speed compared to manual approaches, maintenance time reduction for similar transformations, incident reduction through better quality and lineage, and team productivity gains.
Document onboarding time for team members new to the platform. One of the most compelling benefits is how quickly new team members become productive compared to the months typically required to master manual Databricks SQL development.
Track development cycle time reduction, maintenance burden decrease, quality improvements (fewer production incidents), and onboarding acceleration. These metrics provide concrete ROI justification for broader adoption.
Explore how Coalesce transforms Databricks SQL development through an interactive platform tour to see the visual development interface in action, scheduled demo to discuss your specific requirements and see relevant examples, or the Coalesce Transform product page to understand the full capabilities including Coalesce Copilot AI assistance.
✓ Getting Started Checklist
- Establish baseline metrics (transformation count, development time, incident rate)
- Identify pattern duplication and standardization opportunities
- Assess current lineage and impact analysis capabilities
- Define success criteria for transformation optimization
- Select pilot project scope and team
- Schedule platform evaluation (demo or trial)
- Measure pilot results against baseline
- Plan broader rollout based on pilot learnings
The future of data transformation in Databricks SQL
The data transformation landscape continues evolving rapidly, with several key trends shaping how teams will work with Databricks SQL and lakehouse platforms in the coming years.
AI-assisted development and semantic understanding
AI assistance for data transformation has progressed significantly. Databricks Assistant provides SQL generation from natural language, helping engineers write queries more quickly. AI/BI with Genie enables business users to ask questions in natural language and receive answers without writing SQL. Coalesce Copilot delivers AI-powered transformation workflows, suggesting patterns, generating documentation, and accelerating common development tasks.
The emerging capabilities include more sophisticated code generation that understands business context, automatic optimization suggestions based on query patterns and data characteristics, and self-healing data quality that detects and corrects issues automatically.
The introduction of metric views with semantic metadata in Databricks SQL (a 2025 feature) represents a significant step toward bridging technical and business perspectives. These capabilities map technical column names to business terms, understand relationships between entities, and enable context-aware recommendations. The benefit: technical implementations increasingly understand business semantics, reducing the translation gap between business requirements and technical solutions.
Continuous optimization and unified governance
Databricks’ Predictive Query Execution represents the direction of continuous optimization—systems that adjust execution strategies in real-time based on actual data patterns. The 25% performance improvements in DBSQL Serverless announced at DAIS 2025 demonstrate the ongoing innovation in automatic optimization.
Future capabilities will include self-optimizing transformations that adapt without manual tuning, predictive scaling that anticipates workload changes before they occur, and intelligent resource allocation that balances performance against costs automatically.
Unity Catalog as a central metadata hub extends beyond Databricks, with Delta Sharing enabling open data sharing across platforms and clouds. The trend toward federated governance—consistent policies enforced across diverse platforms—continues accelerating. The future includes more sophisticated cross-platform lineage showing data flow across organizational boundaries, automated compliance monitoring that adapts to regulatory changes, and governance that becomes less burdensome through increased automation rather than more restrictive through manual controls.
Building for scale: Why transformation approach matters
Databricks SQL provides a powerful lakehouse-native data warehouse trusted by over 11,000 customers worldwide for analytics workloads. The platform delivers impressive query performance, seamless BI integration, and comprehensive governance through Unity Catalog. However, as this guide has explored, data transformation remains complex and time-consuming when approached with native tools alone.
- The “T” in ELT continues to be the bottleneck, even on modern platforms like Databricks SQL. While extraction and loading are increasingly automated, and visualization tools are increasingly sophisticated, the transformation layer demands significant manual development effort that slows teams down and introduces technical debt.
- Native tools require substantial manual effort. Whether building transformations with the SQL editor, PySpark notebooks, or Delta Live Tables, each approach requires hands-on coding or configuration. The time investment for enterprise-scale data warehouses is measured in months, and ongoing maintenance consumes significant resources.
- Standardization and governance are critical but difficult to maintain at scale. Without enforced templates and reusable patterns, teams naturally drift toward inconsistency. Governance becomes manual review processes that slow deployment rather than built-in guardrails that enable speed.
- Column-level lineage transforms impact analysis from a time-consuming investigation into an instant query. Understanding exactly which downstream objects depend on each field enables confident, rapid changes and prevents the risk aversion that leads to stagnation.
- Modern transformation platforms address these challenges directly. Purpose-built tools like Coalesce provide visual development that generates optimized code, reusable components implementing proven patterns, automatic lineage at the column level, built-in governance through templates, AI assistance via Coalesce Copilot, and multi-engine flexibility for organizations using multiple data platforms.
- The results are measurable: 10x faster development cycles, 80% reduction in maintenance time, 50% fewer production incidents, and 90% faster onboarding for new team members. These aren’t aspirational goals—they’re documented outcomes from organizations that have adopted modern transformation approaches.
Bottom line: For data engineers and architects working with Databricks SQL, the question isn’t whether to optimize transformation workflows—it’s how quickly to adopt approaches that eliminate bottlenecks and unlock team productivity. As data volumes continue growing and business demands for analytics accelerate, having the right transformation approach becomes increasingly critical for success.
Organizations that thrive will be those that can transform data faster, more reliably, and more cost-effectively than their competitors. Manual development approaches worked when data estates were small, but they don’t scale to modern requirements. Purpose-built transformation platforms provide the acceleration needed to stay ahead—not by replacing Databricks SQL, but by enhancing it with the development experience, governance framework, and productivity multipliers that data teams need to succeed at scale.
Next steps and resources
Explore Coalesce for Databricks SQL
- Interactive Platform Tour – Take a self-paced virtual tour to see Coalesce in action, exploring the visual development interface, column-level lineage, and marketplace packages without requiring a sales conversation.
- Schedule a Demo – Discover how Coalesce helps data teams transform data faster at scale without technical debt. Discuss your specific requirements and see examples relevant to your use cases.
- Coalesce for Databricks – Learn how Coalesce empowers teams to build data pipelines on Databricks with accelerated development, built-in governance, and comprehensive lineage.
- Coalesce Transform – Explore how Coalesce delivers data transformations with built-in structure, AI capabilities via Coalesce Copilot, and integrated governance that scales across your organization.
- Customer Stories – Read real-world results from teams using Coalesce with Databricks and other platforms, including quantified productivity gains and transformation success stories.
Learn more about Databricks SQL
- Databricks SQL Documentation – Comprehensive technical documentation covering all aspects of Databricks SQL, from getting started to advanced optimization techniques.
- Data Warehousing with Databricks SQL – Official product page explaining Databricks SQL capabilities, architecture, and use cases.
- Unity Catalog Overview – Learn about Databricks’ unified governance solution for metadata management, access control, and data lineage.
- Medallion Architecture Guide – Detailed explanation of the bronze-silver-gold pattern for organizing lakehouse data transformations.
Frequently asked questions about Databricks SQL data transformations
Databricks SQL provides several transformation options including the SQL editor for query-based transformations, notebooks for PySpark and Scala code, Delta Live Tables for declarative pipeline management, and Databricks Workflows for orchestration. Each approach offers different balances of flexibility, ease of use, and maintenance requirements.
The medallion architecture organizes data into three layers: bronze (raw data as it arrives from sources), silver (cleaned and validated data with quality checks applied), and gold (business-ready datasets optimized for analytics). This pattern provides clear separation of transformation responsibilities and makes data pipelines easier to understand and maintain.
Databricks SQL supports incremental processing through materialized views with auto-refresh capabilities, streaming tables for continuous data ingestion, and Delta Lake’s merge operations for efficient updates. These features enable processing only changed or new data rather than full table reloads, reducing processing time by 90% or more.
Common challenges include slow development cycles when building transformations manually, accumulation of technical debt through inconsistent code patterns, limited column-level visibility into transformation dependencies, difficulty maintaining standards across growing teams, scalability constraints as transformation count grows, and high technical barriers that create bottlenecks on data engineering teams.
Coalesce accelerates Databricks SQL transformations by providing visual, column-aware development that generates optimized code automatically, pre-built packages for common transformation patterns, automatic column-level lineage for impact analysis, built-in governance through reusable templates, native Git integration for version control, AI assistance through Coalesce Copilot, and the ability to deploy transformations across multiple platforms from a single interface.
p>While Databricks SQL provides a SQL editor and AI-powered assistance through Databricks Assistant, building complex data pipelines typically requires technical SQL or PySpark skills. However, transformation platforms like Coalesce provide visual, approachable interfaces that enable technically-minded business users to build pipelines without extensive coding expertise, as demonstrated by finance teams successfully building production pipelines.
Delta Live Tables (DLT) is a declarative framework for building reliable data pipelines on Databricks. It manages dependencies automatically, provides built-in data quality expectations, and supports the medallion architecture. DLT is ideal for teams wanting simplified pipeline management and automatic dependency resolution, though it has a learning curve and limited customization for complex edge cases.
Key optimizations include enabling Delta Lake’s optimize write and Z-ordering features for faster queries, implementing incremental loading instead of full refreshes, using liquid clustering for automatic data organization, leveraging materialized views for frequently-accessed aggregations, applying filters early in transformation chains, and utilizing Databricks’ Photon engine for improved query performance on compatible workloads.
Databricks SQL now supports Git integration for queries and notebooks, enabling version control for transformation logic. However, managing consistency across different artifact types (SQL queries, notebooks, DLT pipelines) remains challenging with native tools. Transformation platforms like Coalesce provide built-in Git integration that stores all transformation definitions in version control automatically, with support for branching strategies, code review, and CI/CD deployment.