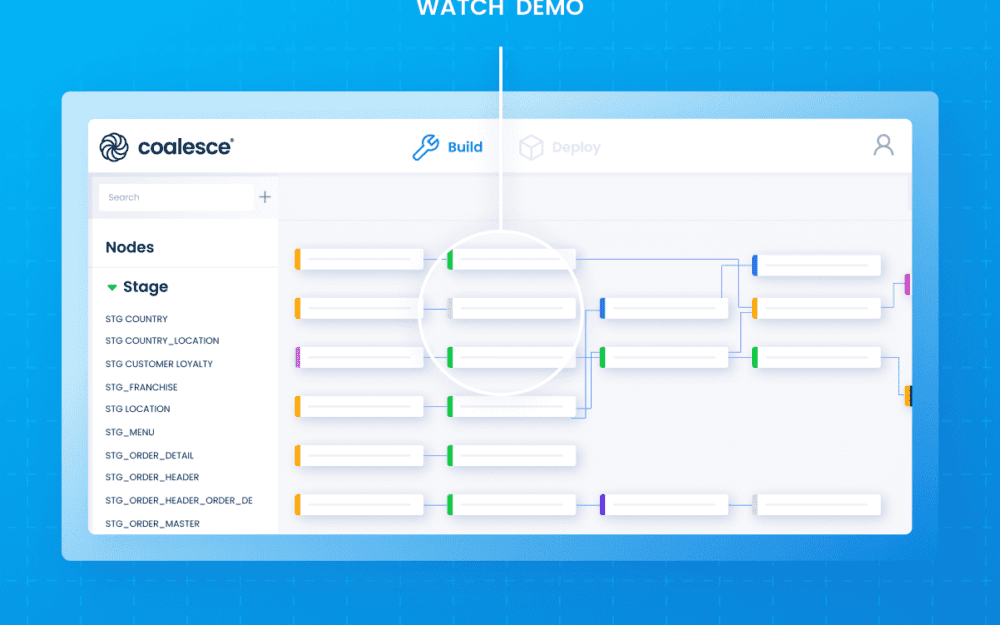
Traditional data warehouses often struggle as companies grow. They tightly couple business rules with how the data is stored, making it harder to scale and adapt. Data Vault 2.0 offers a better way. It separates business logic from raw data structures, making the entire system more flexible and easier to maintain.
This approach helps with common challenges like keeping full audit trails, combining data from different systems, and quickly adjusting to business changes. Its hub-and-spoke design lets you add new data sources without reworking your whole setup. However, building a Data Vault 2.0 system by hand can be slow and complex.
That’s where Coalesce comes in. Coalesce automates much of the heavy lifting—like creating objects and managing transformations—while still giving developers control over logic and deployment. This guide shows how to use Coalesce and Snowflake together to create efficient, scalable Data Vault 2.0 systems.
What is Data Vault 2.0?
Data Vault 2.0 is a data modeling methodology designed to handle change – whether it’s evolving business rules, new source systems, or shifting data structure. Unlike traditional models that can break when new data or schemas are introduced, Data Vault is built to evolve. It structures data into three parts:
- Hubs, which contain unique business keys, such as customer IDs.
- Links, which define relationships between those keys, like which customer placed which order.
- Satellites, which store historical details and descriptive attributes related to the hubs and links.
This separation ensures traceability and flexibility. Using a Data Vault 2.0 approach, you can still leverage cloud optimization, real-time processing, and advanced automation— which is why many large enterprise have adopted it.
While Data Vault 1.0 focused on historized, consistent models, version 2.0 introduces modern capabilities like parallel data loading, metadata-driven design, and cloud automation. It’s purpose-built for today’s enterprise needs, including real-time data ingestion, scalable cloud platforms like Snowflake, and automated data governance.

Data Warehouse and Data Vault Adoption Trends
This global survey of data and analytics leaders highlights the latest data warehouse and data vault adoption trends in modern analytics environments, including architecture types, priorities, and automation.
Data Vault 2.0 architecture in Snowflake
Data Vault 2.0 architecture naturally fits the Snowflake environment. Snowflake offers key features like separation of compute and storage, near-unlimited scalability, and built-in support for semi-structured data—all of which complement Data Vault’s flexible structure.
The architecture starts with ingesting raw data into a Raw Vault, where data is loaded in its original state to preserve fidelity and immutability. From there, transformations can be layered on in a Business Vault, applying business logic, filters, or derived relationships. Finally, data is made available for consumption through curated Data Marts or presentation layers.
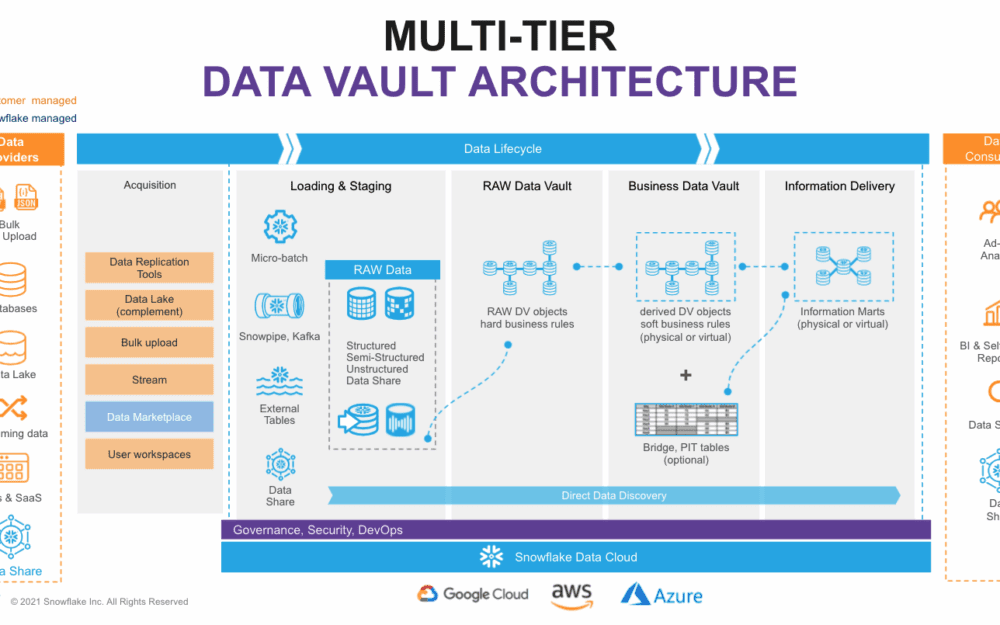 Source: Building a Real-Time Data Vault in Snowflake
Source: Building a Real-Time Data Vault in Snowflake
Snowflake’s elasticity allows you to scale compute resources on demand, so even the heaviest batch or real-time pipelines can execute efficiently. With Coalesce, you can automate and orchestrate every layer—from staging to marts—with full control over transformations and dependencies.
Methodology: How to implement Data Vault 2.0 step by step
A standard Data Vault implementation follows this sequence:
- Requirements Gathering: Start by identifying key business processes and source systems. Focus on capturing unique identifiers that will form your hubs.
- Modeling: Define your Hubs, Links, and Satellites. Determine what data needs to be historized, what relationships exist between entities, and which fields need to be tracked over time.
- Implementation in Snowflake: Use Coalesce to automate table creation, transformation logic, and dependency management across the pipeline.
- Testing and Validation: Ensure lineage, accuracy, and completeness by validating row counts, hash key generation, and timestamp tracking.
- Optimization and Maintenance: Monitor performance, automate updates, and evolve the model as new requirements arise.
Coalesce simplifies this entire workflow. It uses templates and dynamic logic to build repeatable patterns. With Coalesce, developers can create parameterized, reusable pipelines that adapt to different environments—like development, staging, and production—without duplicating work.
How do I deploy a Data Vault?
Choosing the right deployment strategy is critical. Most companies now lean toward cloud-first approaches, using platforms like Snowflake to avoid infrastructure complexity. However, Data Vault also works in hybrid or on-prem environments.
The real power comes when paired with a tool like Coalesce. Coalesce enables fully automated pipeline orchestration, with scheduling, alerts, and monitoring built in. You can manage complex dependencies with ease, and deploy changes confidently thanks to version control and streamlined CI/CD.
Using Coalesce with Snowflake allows you to take full advantage of:
- High concurrency
- Cost-effective storage and compute scaling
- Time Travel and fail-safe recovery for governance and audit needs
Why use Coalesce for Data Vault 2.0?
Implementing Data Vault 2.0 manually is possible, but incredibly time-consuming. You’d be responsible for creating the code for every table, track every transformation, and manage dependencies on your own.
Coalesce offers a different approach focused on accelerating your time to value:
- Auto-generated hub, link, and satellite templates
- Dynamic parameterization so one pipeline can work across environments
- Column-aware architecture that tracks lineage and transformation logic down to individual fields
- Built-in governance, including data documentation, naming standard enforcement, and version tracking
It also supports advanced features like hash key generation and type 2 historization—all without writing custom code.
Teams using Coalesce have reported 10x faster implementation times, better collaboration between engineering and analytics, and far fewer errors in production. As a bonus, your entire Data Vault architecture is visually represented, making it easy to debug and optimize.
“There are a lot of tools that promise that they can make Data Vault easier, but Coalesce is in the sweet spot of control and ease of use. We were really impressed by that on day one.”
Ivo Goudzwaard
Data Engineering Specialist, Boels
What are the challenges of implementing Data Vault 2.0? (and How Coalesce Solves Them)
Implementing Data Vault 2.0 can be powerful—but it’s rarely straightforward. According to a global survey of data and analytics leaders:
- Only 33% of adopters say their implementation fully aligns with Data Vault 2.0 standards for architecture, methodology, and modeling.
- Only 65% report having received proper training, leading to knowledge gaps and inconsistent practices.
Top challenges cited include:
- 50% struggle with poor data quality
- 49% face dependency on a few individuals or consultants
- 37% lack automation, which slows delivery and introduces risk
Many teams overcomplicate models, get bogged down generating hash keys, or lack consistent approaches across departments. Manual rework becomes a recurring problem—especially when business rules change. And for over a third of respondents, persistent data silos continue to degrade quality and productivity.
Coalesce directly addresses these pain points:
- Enforces consistent naming conventions and reusable transformation patterns, reducing reliance on tribal knowledge.
- Automates tedious tasks like hash key generation and documentation, reducing manual effort and risk.
- Offers a visual, metadata-driven interface that shows column-level lineage—making it easier to assess the downstream impact of changes and prevent costly errors.
- Aligns with industry recommendations: doubling down on data quality, focusing on fundamentals, and automating with commercial tools—a strategy followed by 62% of best-in-class companies, versus just 24% of laggards.
By simplifying implementation and empowering teams to build governed, scalable architectures, Coalesce helps organizations get Data Vault 2.0 right—faster.
Build better, scale faster: Your Data Vault 2.0 blueprint starts here
Data Vault 2.0 is a scalable, governed, and flexible data architecture. It provides the framework enterprises need to manage growing data complexity while staying agile. With Coalesce, you get the power to build, manage, and automate those models with unmatched speed and confidence, leveraging the power of Snowflake to Scale your data modeling
If you’re looking to simplify your modern data stack, reduce manual work, and scale your pipelines faster, Coalesce is your ideal partner for Data Vault 2.0 implementation in Snowflake.
Design, transform, and automate your data models—all in one place.