Let’s take a look at two common approaches to building complex processing with SQL in an analytical environment: common table expressions (CTEs) vs. pipelines. Processing in an analytical environment, such as a data warehouse, is often used to apply data rules and business rules to potentially large, raw data sets to prepare them for consumption by data science, business intelligence (BI), or reporting tools.
Complex processing is usually broken down into steps, the output of earlier steps feeding into the input of later steps. In this way, the complexity is broken down into less complex and easier to understand steps. This article seeks to identify the factors that would help a developer decide which approach is best between CTE-based SQL or pipeline-based SQL (made up of several SQL steps linked by metadata in a platform like Coalesce).
In more detail:
- CTEs are used to embed complexity in several SQL blocks pulled together into a single SELECT or DML operation. This is a more fashionable incarnation of achieving the same using inline views. Here’s an example query using WITH to define CTEs containing SQL blocks:
SQL using CTEs to combine Customer and Order data
- Pipelines are made up of independent SQL blocks persisted with DDL (e.g. views / tables) and combined into a Pipeline or DAG (directed acyclic graph). The DAG defines the dependencies and execution order of the SQL blocks in the Pipeline. The Coalesce platform is optimized to help a developer build, manage, deploy, document, and execute the Pipeline or DAG using a graphical interface:
 Pipeline combining Customer and Order data
Pipeline combining Customer and Order data

Other processing approaches that are not expanded upon in this document include:
- Cursors: row-by-row processing in SQL, which is typically much slower than Set-Based Design (SBD) approaches considered here.
- Non-modularized SQL: trying to use correlated subqueries and big complex / repetitive SQL functions in a single SQL statement. This approach often leads to much more complex SQL statements.
- Inline views: using SELECT statements in the FROM clause, for example:
This approach is similar to CTE-based SQL, but harder to read.
- ETL processing: requires a separate processing engine to apply processing. This is considered a legacy approach and is not considered in this discussion.
The factors to consider when choosing the optimal approach are:
- Performance: Which approach is more scalable, faster to execute, and by how much. Typically, processing data in a data warehouse involves large amounts of data, so performance matters. If we need to process the data every 15 minutes and the process takes 15 minutes or more, then the system is always busy (which is also expensive).
- Tuning: Performance and compute consumption in cloud based databases (like Snowflake) results in a higher execution cost in real dollars.
- Troubleshooting / Support: When the figures are not right or the code breaks, how quickly can a cause and a fix be determined. Support effort has a long term implication for cost – typically, SQL processing in a data warehouse could be around for years and is supported by a different person or team than the original author. If it takes an hour to fix a problem in production vs a day or a week, then that could have a significant impact on your choice.
An example
A comparison is made using a relatively simple example where we use CTEs to modularize a complex multi-step logic over Snowflake sample data. Here we can see CTEs defined in the WITH area of the query using SQL to apply data rules, business rules and filtering to the data, using the results from one named CTE in the body of another until we pull together the results into a SELECT at the bottom.
This style of SQL can be useful to link together a series of statements into a single query—and it can get very big and unwieldy. It’s not uncommon to see queries of many hundreds of lines.
Over the Snowflake TCPH sample data (SNOWFLAKE_SAMPLE_DATA.TPCH_SF10), this query executes in 3.3 seconds to return 100K rows using an X-Small warehouse. A portion of the query execution plan is shown below:
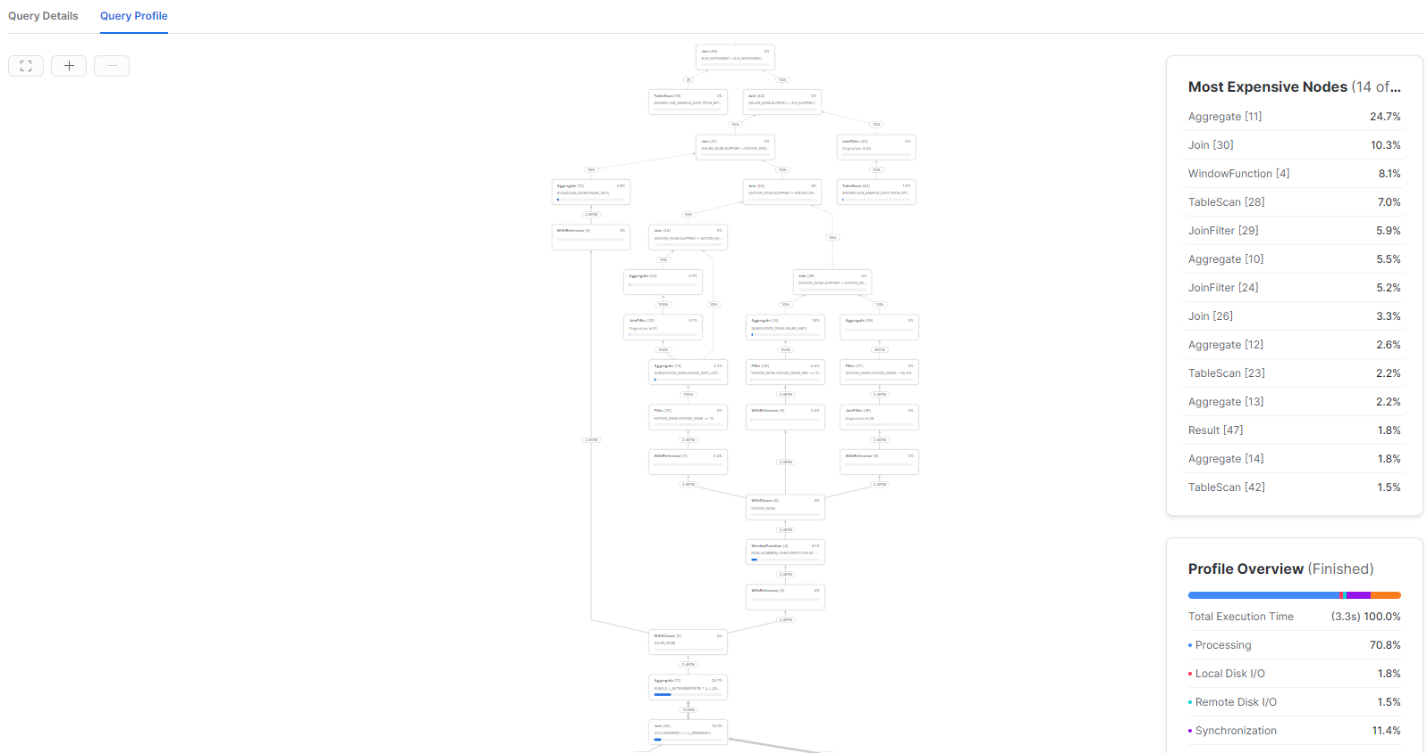
Identical processing built using views generated in Coalesce with a pipeline looks like this:
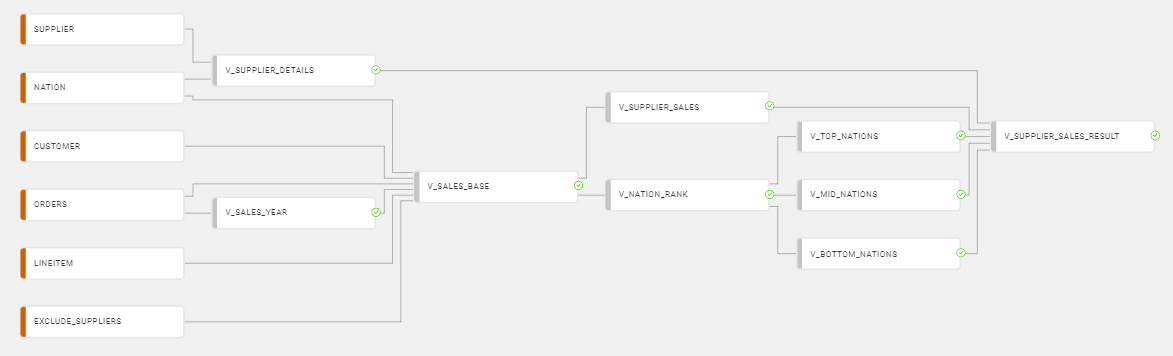
In this example, views were built one-for-one with the CTEs in the preceding query using Coalesce. In this case, successor views select from views earlier in the pipeline. Each node in this example could also be generated as a table with associated DDL and DML if it helped with query tuning. Selecting data from the final view (V_SUPPLIER_SALES_RESULT) returns the same result set as the CTE-based query and has a total execution time of 2.8 seconds and shows a more parallel execution plan (which should scale better over larger data volumes).

Comparing CTEs vs. pipelines in four key areas
Both styles of SQL development can be built to yield identical results with similar execution performance. As mentioned earlier, this query could be written in a number of different styles – but the CTE-based approach was used to compare directly with a SQL pipeline using views.
Here is how the two approaches compare in four key areas:
Development
-
- The CTE based SQL query took about 90 minutes to build and troubleshoot, whereas the pipeline took around 15 minutes. The pipeline is easier to troubleshoot during development because each step can be built, queried, tested, and changed independently. The CTE SQL had to be modified each time in order to run an individual CTE. For example, troubleshooting the LISTAGG function in the top_nation_sales CTE took a few goes to get right and each time the query needed to be modified to run the failing CTE. It’s not possible to run the CTE on its own, it needs all the predecessor CTEs to be included in the query and none of the successor CTEs to test it. Also, during development and testing some SQL error messages are not precise and fail without displaying a line number to help locate the problem (such as ambiguous column name error), so the developer is left scanning the full SQL statement for the problem.
Tuning
The CTE based SQL can be rewritten, but optimization options will not be as flexible as the pipeline approach. Each step in the pipeline can be converted to a table (for example, transient, persistent or non-persistent) from a view with a mouse click, and this step can then be pre-prepared offline using a job. In addition, the pipeline could easily be converted to incremental processing at any step by persisting the end resultset into a table and recording the latest change / modified date. Any subsequent reruns could filter the input dataset to only include newer or changed data.
Testing
Coalesce supports the development and execution of SQL-based tests (for example, checking for uniqueness or nulls) at each node along the pipeline. This ensures that unsupported data that results in a technical or logical failure can be identified along the pipeline without having to wait till the end of the processing to find out the data is wrong.
Troubleshooting
If a problem is identified with the output data—or a technical failure occurs with the processing—the ability to see the flow of data and the ability to independently run and test the data at each stage of a pipeline offers a huge advantage over troubleshooting the CTE-based query. A developer would need to read through the whole query to determine how it worked and the dependencies between CTEs, and then take apart the queries in order to run the components to identify a problem. This reduced support overhead of the pipeline approach has a significant impact on the lifetime cost of managing complex processing and should be a major factor when choosing a processing approach.
Why Coalesce
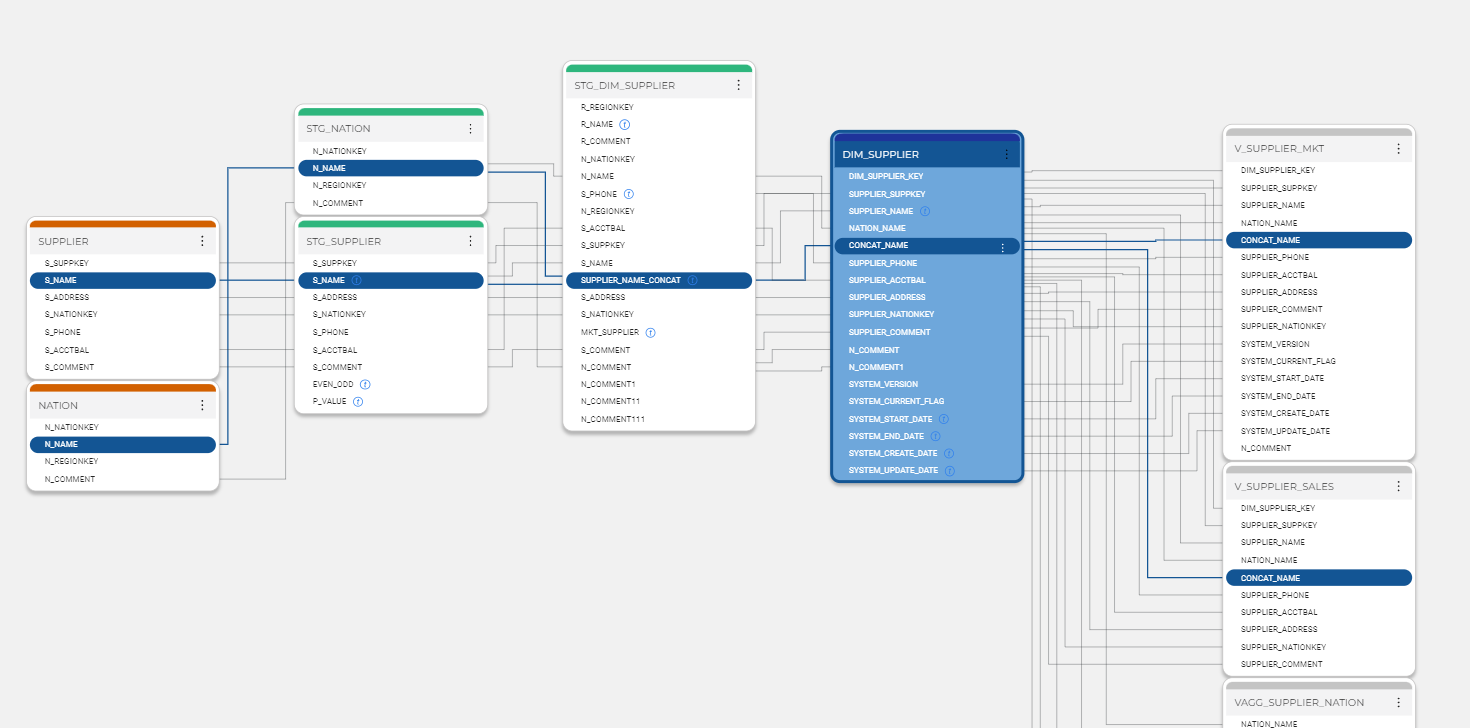
Coalesce is a metadata-driven transformation solution that generates and pushes transformation code down into Snowflake. Metadata is used to generate code to speed up the development of any pattern-based processing, such as data vault or dimensional designs. The metadata also helps to manage the environment by providing data lineage documentation which can be used to identify data origination and usage paths. Metadata can also help manage change across a pipeline, such as propagation of a new column:
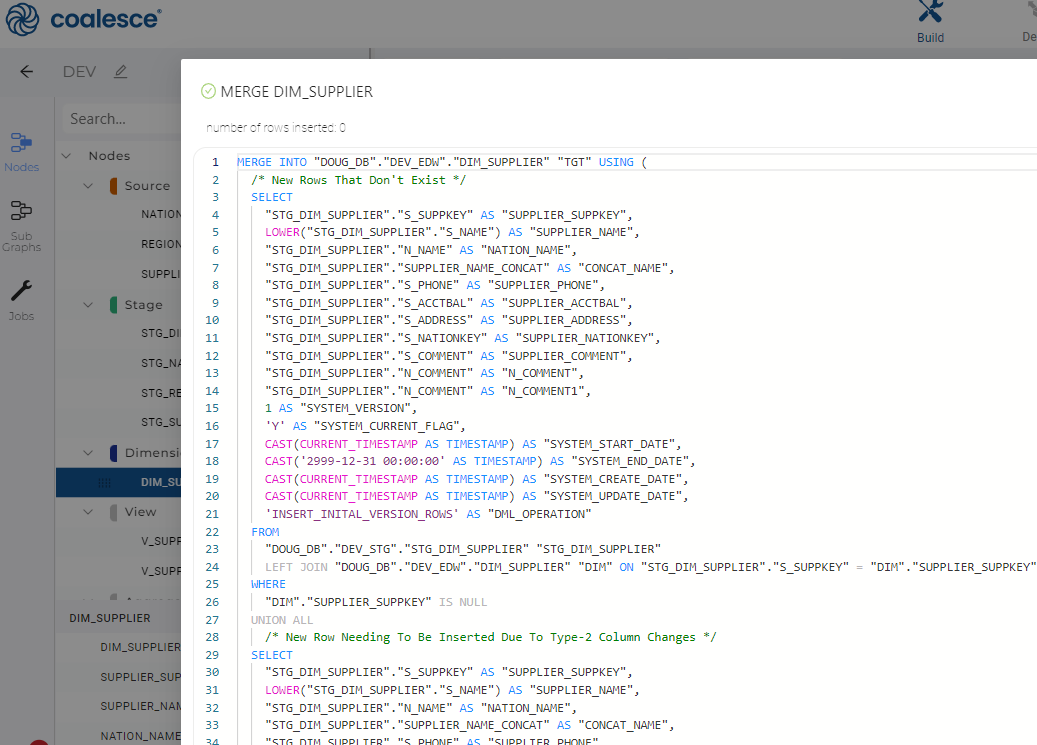
Code generation using customizable templates in Coalesce ensures that processing code follows a standard, is quick to build or rebuild, and is consistent regardless of who is driving the keyboard. For example, building a Type 2 dimension in metadata and then generating the DDL and DML to create and populate it (and running it) takes seconds:
Once developed, the code can be committed into a GIT-based repository within Coalesce and then deployed to downstream environments such as QA and Production.
Want to see for yourself? Try Coalesce for free or request a demo.