Key Takeaways
A data glossary (or business glossary) defines key business terms in plain language, ensuring teams across the organization share the same understanding of metrics and concepts. Unlike a data dictionary, which documents technical metadata, the glossary creates semantic clarity that drives trust, governance, and consistent reporting. A modern data catalog connects both—linking business definitions to technical metadata—so users can discover, understand, and trust their data, enabling true self-service analytics.
Understanding how a business defines and organizes its core terms is foundational to building a scalable data strategy. But what is a data glossary—and how is it different from a data catalog or a data dictionary?
As data ecosystems grow in size and complexity, it becomes increasingly difficult for teams to align on core metrics. A data glossary solves that challenge by creating a common language across departments. This shared context makes data more accessible, trustworthy, and actionable—especially when paired with the right metadata and transformation infrastructure.
What does a data glossary do?
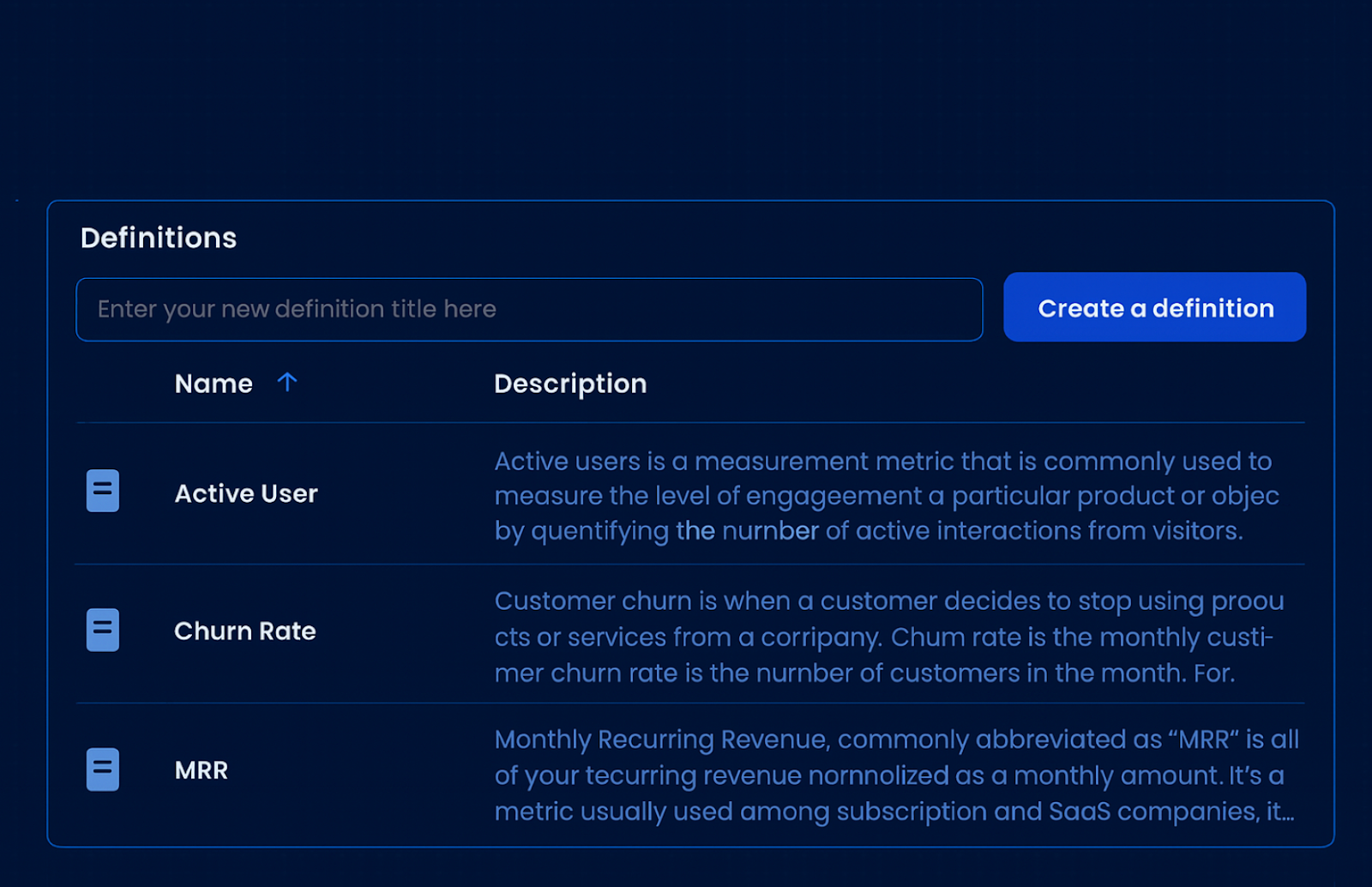
A data glossary—also known as a business glossary—is a curated list of business terms with clear definitions. It ensures everyone in the organization uses the same terminology when discussing key concepts like “customer,” “churn,” or “MRR.”
At its core, the glossary establishes semantic clarity across business and technical teams. For example, if your sales team defines “active customer” as someone who purchased in the last 30 days, but your analytics team defines it as anyone who’s logged in during the past week, it’s nearly impossible to produce consistent reporting.
By codifying definitions, a business glossary acts as a single source of meaning—making it easier to calculate KPIs, build trust in reporting, and accelerate decision-making.
- Learn how Coalesce Catalog helps organizations establish a single source of context across technical and business users.
Why is a data glossary important?
A well-maintained glossary benefits every part of the business:
- Measuring what matters: KPIs only mean something if everyone agrees on what’s being measured. Glossaries reduce ambiguity by defining each term, ensuring consistent metrics across dashboards and reports.
- Building trust in data: When stakeholders see conflicting results, confidence in the data erodes. A shared glossary brings transparency to definitions and helps teams understand where discrepancies originate.
- Driving governance: Glossaries also support data governance by identifying sensitive terms (e.g., PII) and linking them to related access policies or data quality rules.
When paired with metadata tools like data dictionaries and transformation lineage, glossaries form the foundation of scalable, governed self-service analytics.
How is a data glossary different from a data dictionary?
Although the terms are often used interchangeably, a data glossary and a data dictionary serve distinct but complementary roles:
Data glossary (business-facing): A glossary defines business concepts in plain language, so that everyone across the organization shares the same understanding. For example, it might define “Revenue” as “Total invoiced amount before discounts.” Its goal is to reduce ambiguity and ensure that teams are speaking the same language.
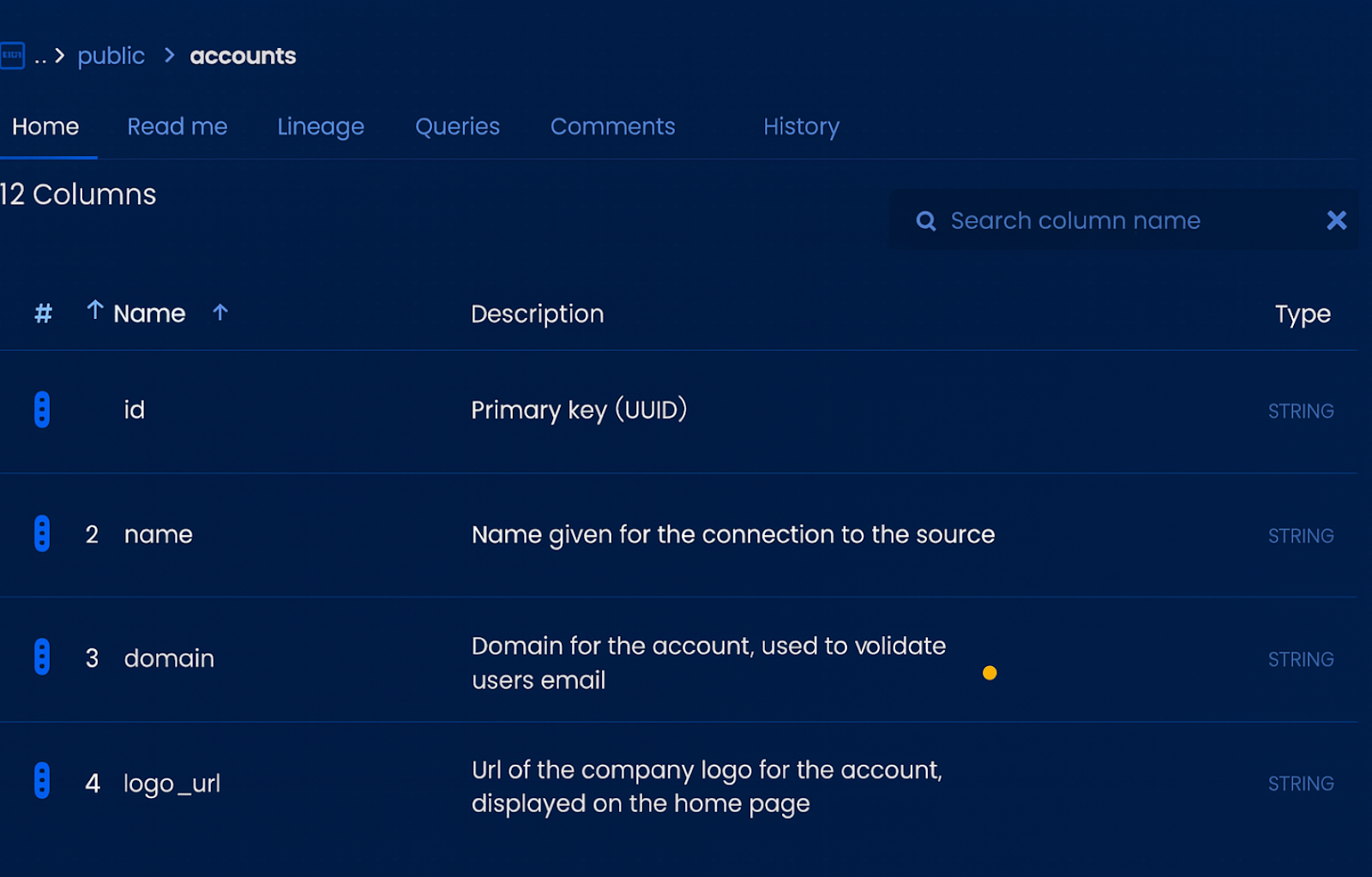
Data dictionary (technical-facing): A dictionary describes the metadata and structure of physical data assets — things like column names, data types, and table relationships. In the same example, the dictionary would show that revenue is stored in the rev_total column of the sales_orders table as a FLOAT.
Think of it this way: the glossary tells you what a concept means in the business, while the dictionary tells you where and how that concept lives in your systems.
On their own, each tool is incomplete — business users can’t rely only on column names, and engineers can’t rely only on business definitions.
That’s why many organizations turn to a data catalog, which connects the two: linking business definitions to their technical counterparts so both business and technical teams can find, understand, and trust their data.
What is a data catalog—and how does it tie everything together?
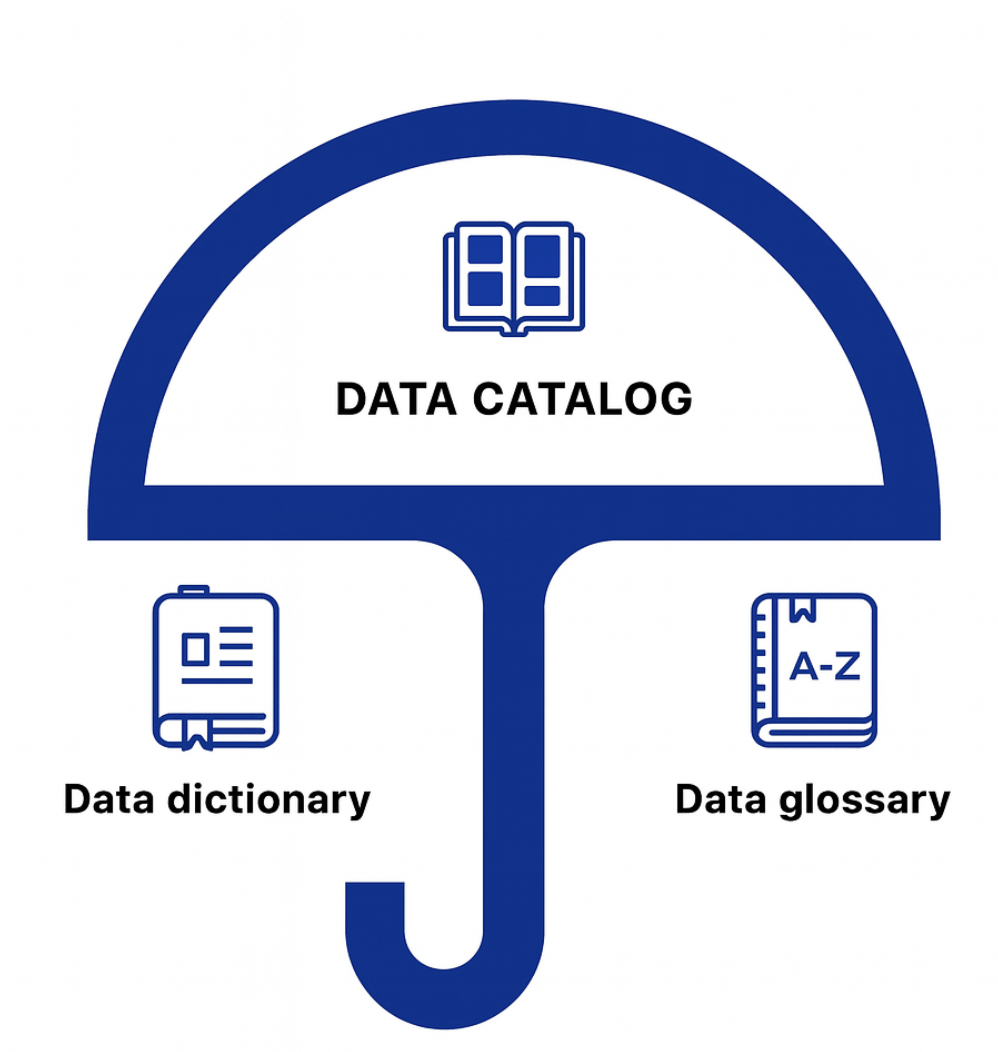
A data catalog unifies glossaries and dictionaries in one searchable platform. It connects business context with technical metadata, so users can move from “What does churn mean?” to “Where is churn calculated in the warehouse?”—all in a single interface.
With the Coalesce Catalog, for example, business users can search for a term like “churn,” find its glossary definition, see which data assets contribute to it, and trace how it’s transformed using column-aware lineage.
This connection between business and technical context drives two key outcomes:
Faster, more accurate analysis: Analysts can tie metrics directly to source columns and tables without needing to dig through documentation or ping the data team.
True self-service: When marketing or operations teams can search for terms, understand them, and trace them back to the data—without writing SQL—it unlocks a whole new level of autonomy.
- See how United Community Bank reduced redundant datasets and simplified documentation with Coalesce: Read the customer story
What should you look for in a modern data catalog?
A modern catalog should offer more than static documentation. Explore our list of the top 10 data catalog tools in 2025 here.
Key capabilities include:
- Business glossary and metadata integration: Tying definitions to data assets for traceability
- Column-aware lineage: Visualizing transformations down to the column level
- Role-based access controls: Managing sensitive terms like PII with precision
- Automated documentation: Using AI to populate definitions and suggest related terms
- Search and discovery: Empowering all users to navigate the data landscape
Coalesce Catalog delivers all of the above—designed for organizations that want to scale governance and transparency without slowing down transformation work.
- Learn more about the Coalesce Catalog and how it works by taking a product tour here.
- Ready to speak with a Coalesce product expert? Book a demo here.
Frequently Asked Questions
They’re the same thing. Both terms refer to a curated list of business terms and their agreed-upon definitions, designed to align technical and non-technical teams around a common language.
A data dictionary describes technical details—such as column names, data types, and table relationships—but doesn’t explain what those terms mean in the business context. A glossary provides that plain-language clarity. The two are complementary: one explains the “what it means,” the other the “where it lives.”
By standardizing definitions, a glossary removes ambiguity from metrics and reports. Teams can trust that KPIs are calculated the same way across departments, leading to faster, more confident business decisions.
A data catalog ties everything together. It connects glossary definitions with their technical counterparts in the dictionary and layers on metadata, lineage, and governance capabilities. This helps users move seamlessly from understanding a term to locating and analyzing the data behind it.