Key Takeaways
Data transformation is the “T” in ELT: turning raw data into clean, structured, analytics-ready datasets. In 2025, transformation tools go beyond SQL, combining automation, governance, and AI to handle growing data complexity. The right tool can speed development, enforce standards, and integrate documentation at the source. This guide compares 10 of the most populat transformation tools of 2025, from modern cloud platforms to open-source frameworks.
What is a data transformation tool?
Think of a data transformation tool like a data workshop, it takes messy, raw data from many sources and turns it into something clean, organized, and ready to use.
In the past, this work happened in all-in-one ETL systems tied to on-premise servers. Now, with ELT, most transformations happen right inside the data warehouse or lakehouse, where the processing power is faster and the setup is easier to manage. Platforms like Coalesce make this even smoother by combining automation, governance, and AI in one place.
Modern tools do more than just run SQL. They can:
- Automatically handle task order and testing
- Add documentation and show where data came from
- Work across different environments and connect to CI/CD
- Give non-coders simple drag-and-drop options
- Use AI to help write, improve, and document code
Whether you like coding everything yourself or prefer a visual tool like Coalesce and other transformation platforms now make it faster and easier for teams to work together and keep data reliable.
Why use a data transformation tool in 2025?
In today’s modern data stack, transformation has become the biggest bottleneck. With data flowing in from dozens of SaaS apps, APIs, and internal systems, teams often end up with scattered SQL scripts, slow and error-prone deployments, inconsistent metric definitions, and outdated documentation that makes lineage hard to trust.
A modern transformation tool solves these problems by automating repetitive work, enforcing standards with built-in testing and CI/CD, keeping documentation and lineage accurate in real time, and enabling technical and business teams to work seamlessly together. The result is trusted, analytics-ready data delivered faster—without the chaos.
In this guide, we explore 10 leading transformation tools of 2025, from enterprise mainstays to open-source favorites. We’ve focused on tools that appeared most frequently in analyst research and are widely recognized in the industry for their popularity and brand visibility. While our selection is somewhat subjective, it reflects the platforms that many data teams are actually evaluating or using today.
What are the top data transformation tools of 2025?
1. CoalesceScalable data transformation and AI-powered cataloging |
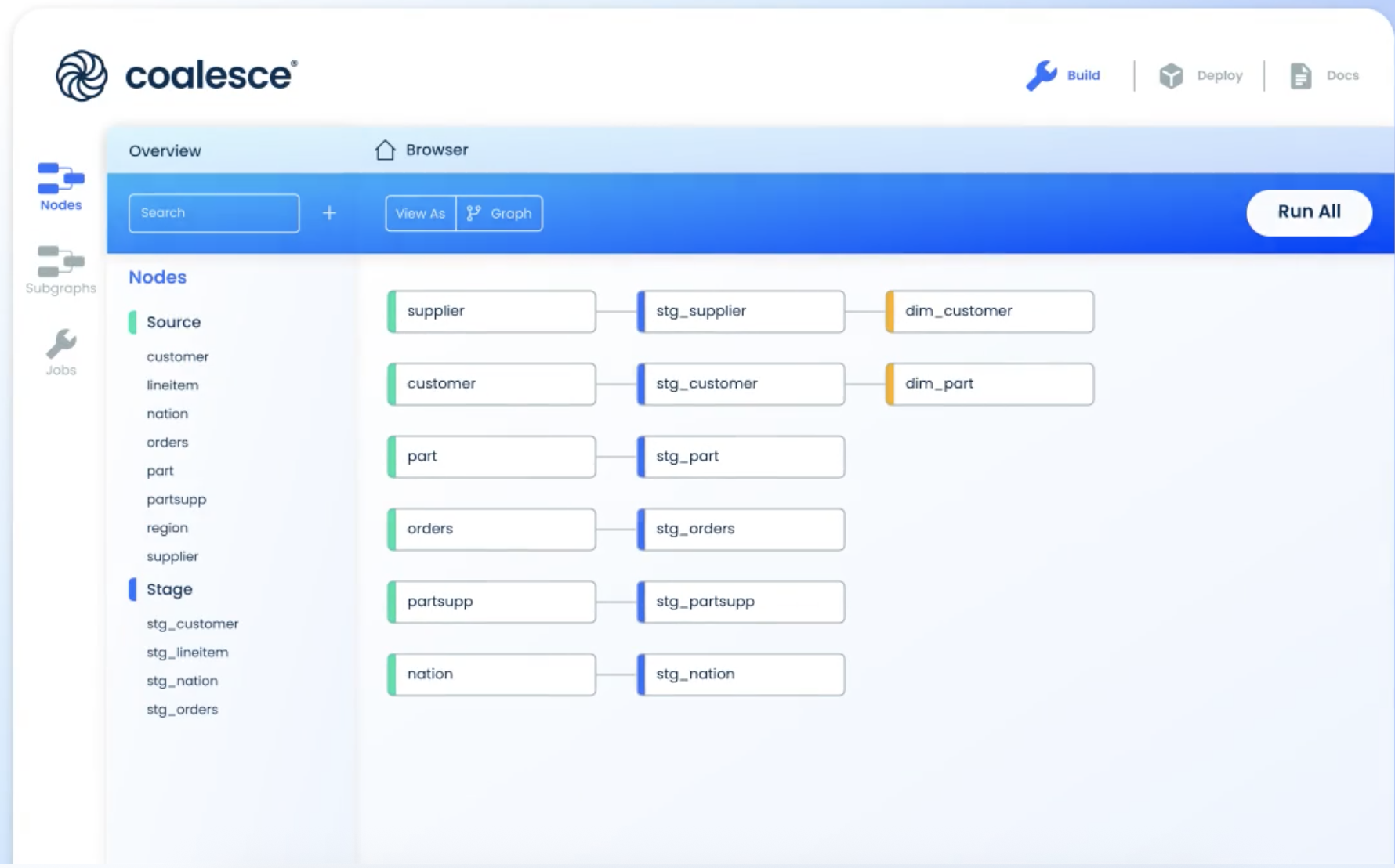
Best for: Modern data teams that want to build, document, and govern transformations in one place-without the sprawl or manual effort.
Coalesce is a modern data development and governance platform designed to help data teams deliver trusted, discoverable data 10x faster with scalable data transformation and AI-powered cataloging solutions.
The platform empower all data pros—ranging from data engineers and architects to data scientists and analysts—through an intuitive visual interface and modular development approach, without sacrificing the power and control of a CLI.. Coalesce currently supports Snowflake, Databricks, and Microsoft Fabric data platforms.
By pairing an intuitive GUI with flexible code-first capabilities, Coalesce helps data teams ramp up quickly and maximize their impact by accelerating data preparation and eliminating rote tasks with bulk editing capabilities and automatically generated, optimized SQL.
Get started with Coalesce today or take an interactive, virtual tour of the platform.
Key Features:
- Column-Aware Automation: Change a column once; updates propagate across all dependent models
- Reusable Templates: Standardize logic and enforce best practices
- Built-In Governance: Role-based access control and audit-friendly metadata
- Multi-Platform Support: Snowflake, Databricks, and Microsoft Fabric.
- AI Assistance: Coalesce Copilot for code generation, optimization, and documentation
Potential Drawbacks:
- Limited data platform support: Currently, Coalesce only supports Snowflake, Databricks, and Microsoft Fabric—though support for BigQuery and Redshift are coming soon.
- Fewer community resources: As a relatively new vendor in the space (compared to legacy mainstays), there are fewer community resources online, especially compared to some open source tools.
- Learning curve: Visual GUI and optional code-first workflow can be unfamiliar (compared to other tools) at first.
👉 Request a custom demo or start your free trial to see how Coalesce replaces complexity with speed, governance, and clarity.
💰 You can also request pricing here.
2. MatillionNo-code ELT with enterprise reach |
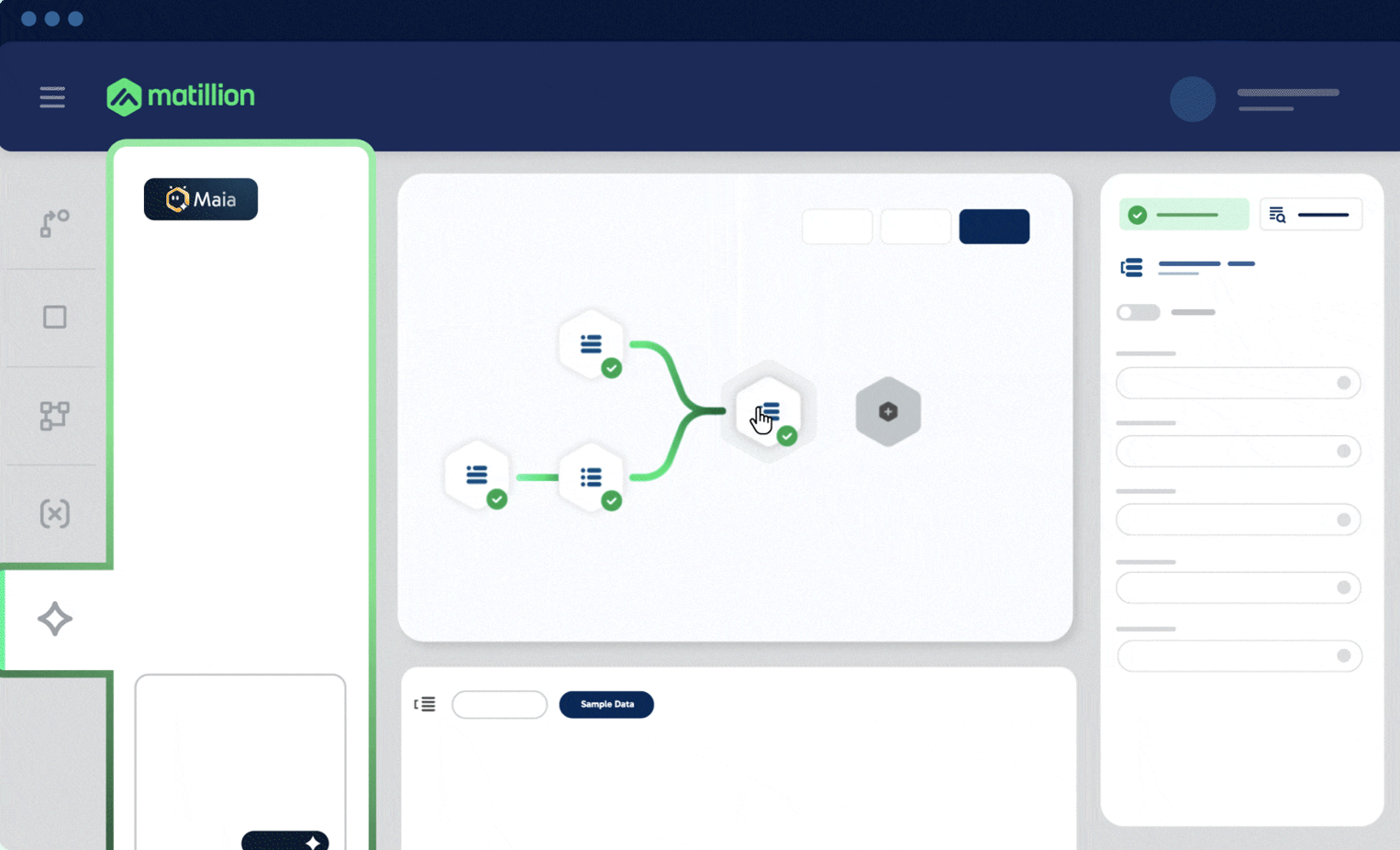
Best for: Teams wanting a visual interface for building transformations directly in their cloud warehouse.
Matillion blends no-code transformation components with SQL execution inside the warehouse, making it accessible to analysts and engineers alike.
Key Features:
- Visual design with drag-and-drop components
- Executes native SQL in Snowflake, BigQuery, Redshift, and Databricks
- Extensive library of pre-built transformations and connectors
- Enterprise-grade orchestration and monitoring
Potential Drawbacks:
- Limited flexibility: Drag-and-drop design may struggle with highly complex or custom transformations.
- Vendor dependency: Tight coupling with specific cloud ecosystems.
3. Google BigQuery DataformNative GCP SQL Orchestration |
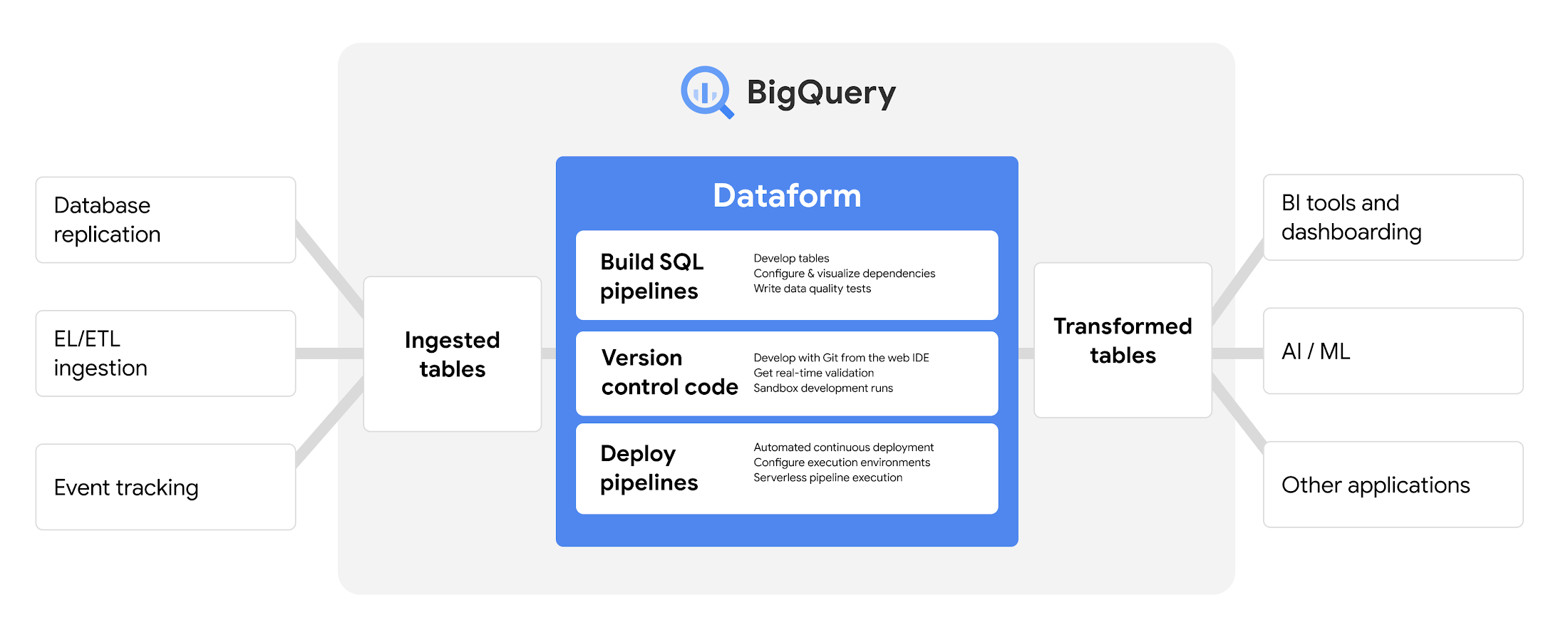
Best for: GCP-native teams building transformations in BigQuery.
Overview: Originally an independent startup, Dataform was acquired by Google and is now fully integrated into BigQuery as BigQuery Dataform—a built-in way to orchestrate SQL pipelines.
Key Features:
- Web-based IDE for SQL model development
- Dependency management and scheduling
- Tight integration with BigQuery permissions and resources
- No additional infrastructure required for GCP users
Potential Drawbacks:
- GCP-only: Works exclusively with BigQuery and GCP stack.
- SQL-centric: Limited options for scripting beyond SQL.
4. Informatica Cloud Data IntegrationHybrid ELT/ETL |
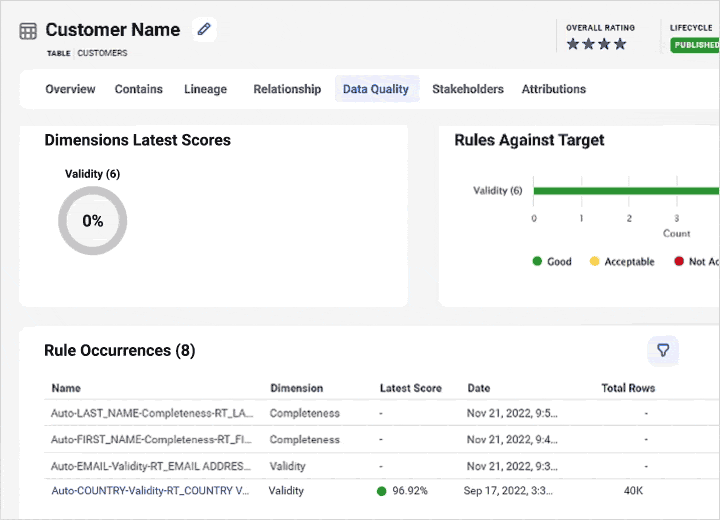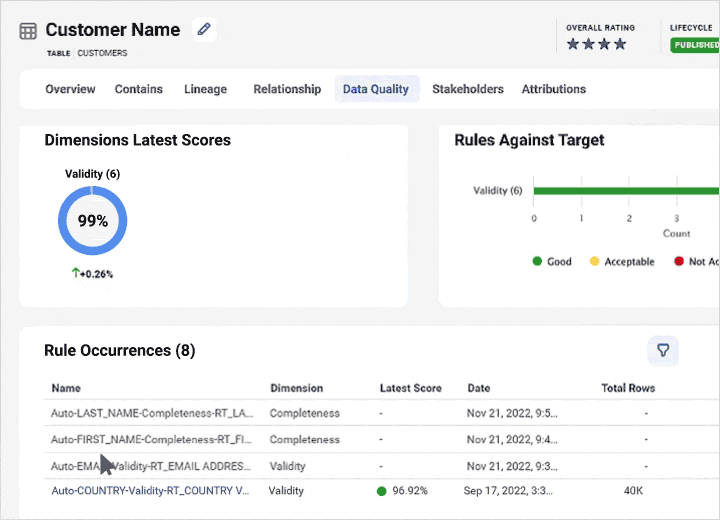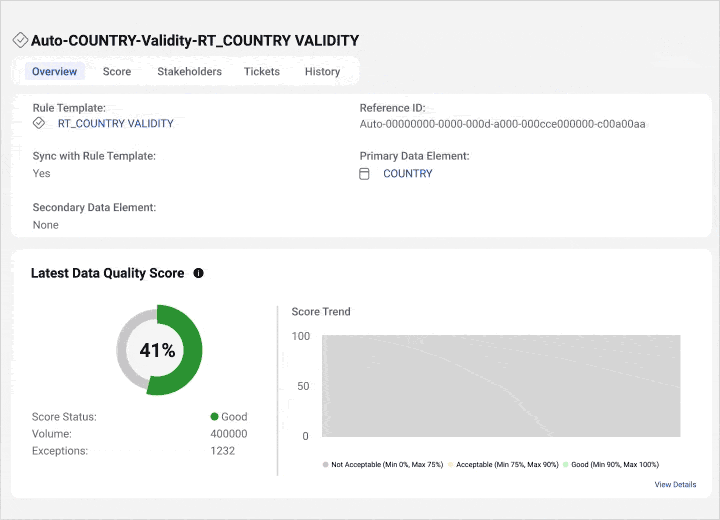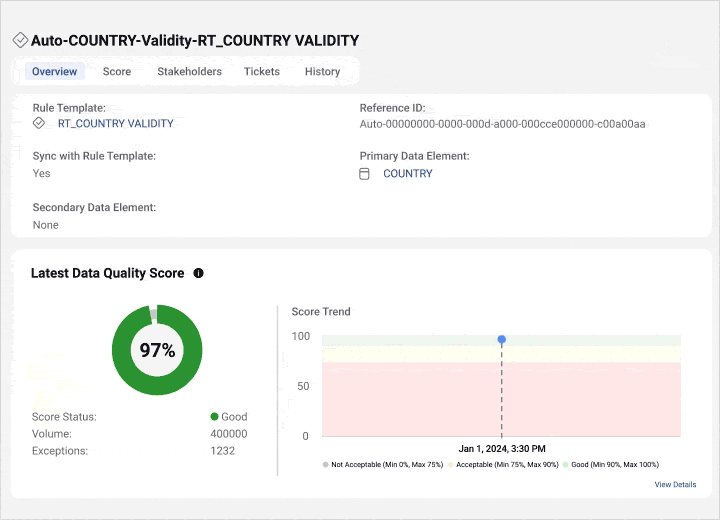
Best for: Large enterprises with hybrid environments and advanced governance requirements.
A veteran in the data space, Informatica’s cloud-native integration suite includes transformation features alongside AI-assisted mapping and broad platform compatibility.
Key Features:
- Visual mapping and transformation logic builder
- Hybrid cloud/on-prem support
- AI-driven schema mapping and optimization
- Strong metadata and lineage integration
Potential Drawbacks:
- Complexity and cost: Enterprise-grade governance comes with higher costs and steep learning curve.
- Maintenance overhead: Hybrid environments require more setup and configuration.
 |
5. AlteryxSelf-service data prep at scale |
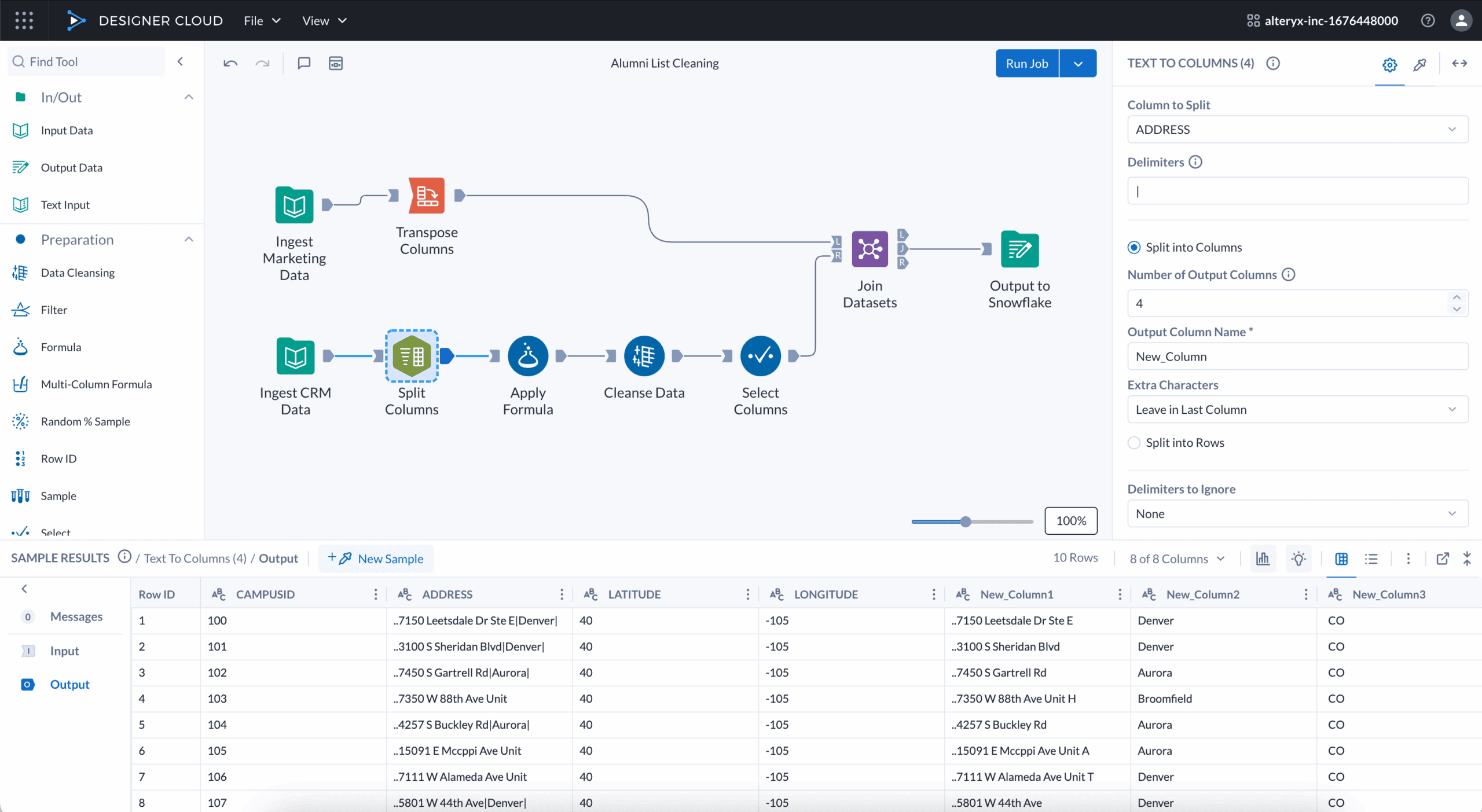
Best for: Analysts and business users preparing data without writing SQL.
Alteryx Designer Cloud (formerly Trifacta) offers a no-code interface for data wrangling, with automated suggestions, profiling, and visual workflows. It is designed for quick, iterative preparation and integrates with a range of data platforms.
Key Features:
- Intuitive, spreadsheet-like interface
- AI-driven cleaning and transformation suggestions
- Real-time data profiling
- Integrations with major warehouses and BI tools
Potential Drawbacks:
- Less control: Visual wrangling is limited for highly customized logic.
- Licensing costs: Enterprise scaling can be expensive.
 |
6. ProphecyLow-code data engineering for Spark and SQL |
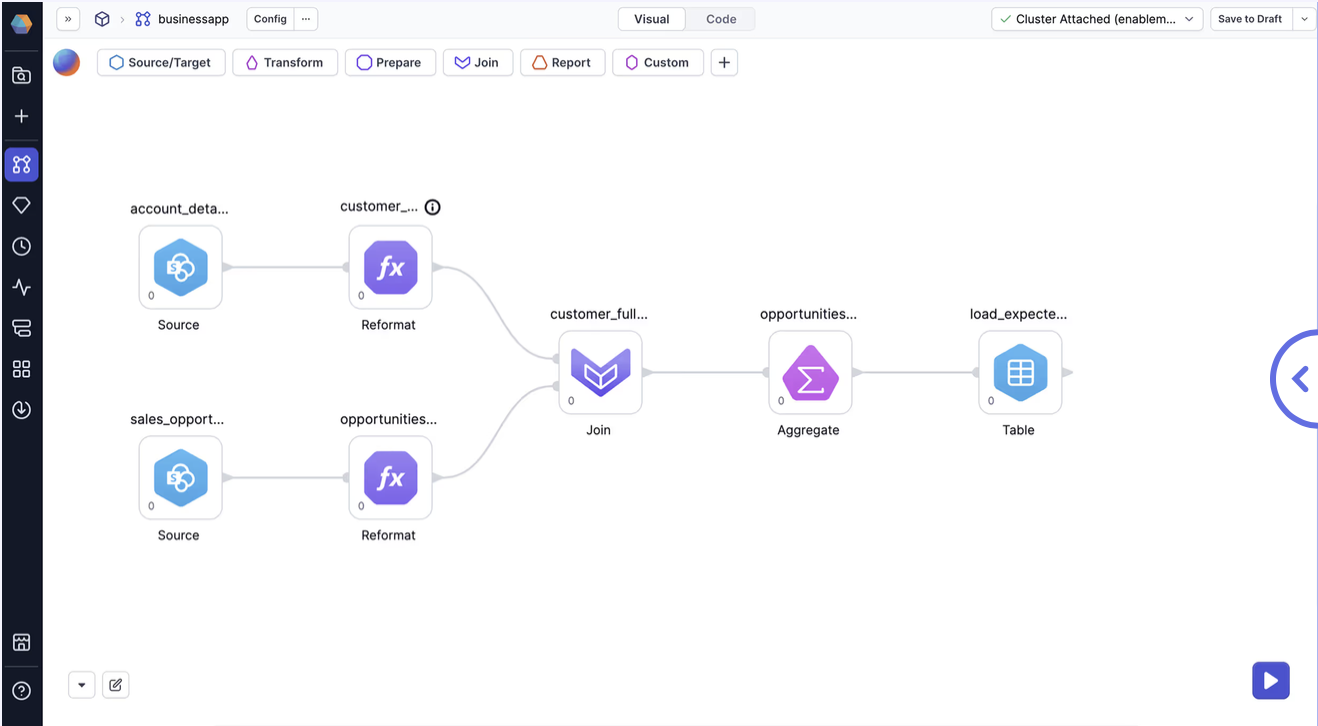
Best for: Teams running both SQL and Spark pipelines with mixed skill sets.
Prophecy lets you build transformations visually while generating production-grade Spark or SQL code under the hood.
Key Features:
- Drag-and-drop builder with code export
- Supports Spark, Databricks, Snowflake, and BigQuery
- Git-based version control integration
- Ideal for teams with both coders and non-coders
Potential Drawbacks:
- Spark expertise required: Low-code but still demands knowledge of distributed systems.
- Vendor dependency: Specialized platform may reduce flexibility if moving to open-source alternatives.
 |
7. SQL MeshOpen-source SQL transformation |
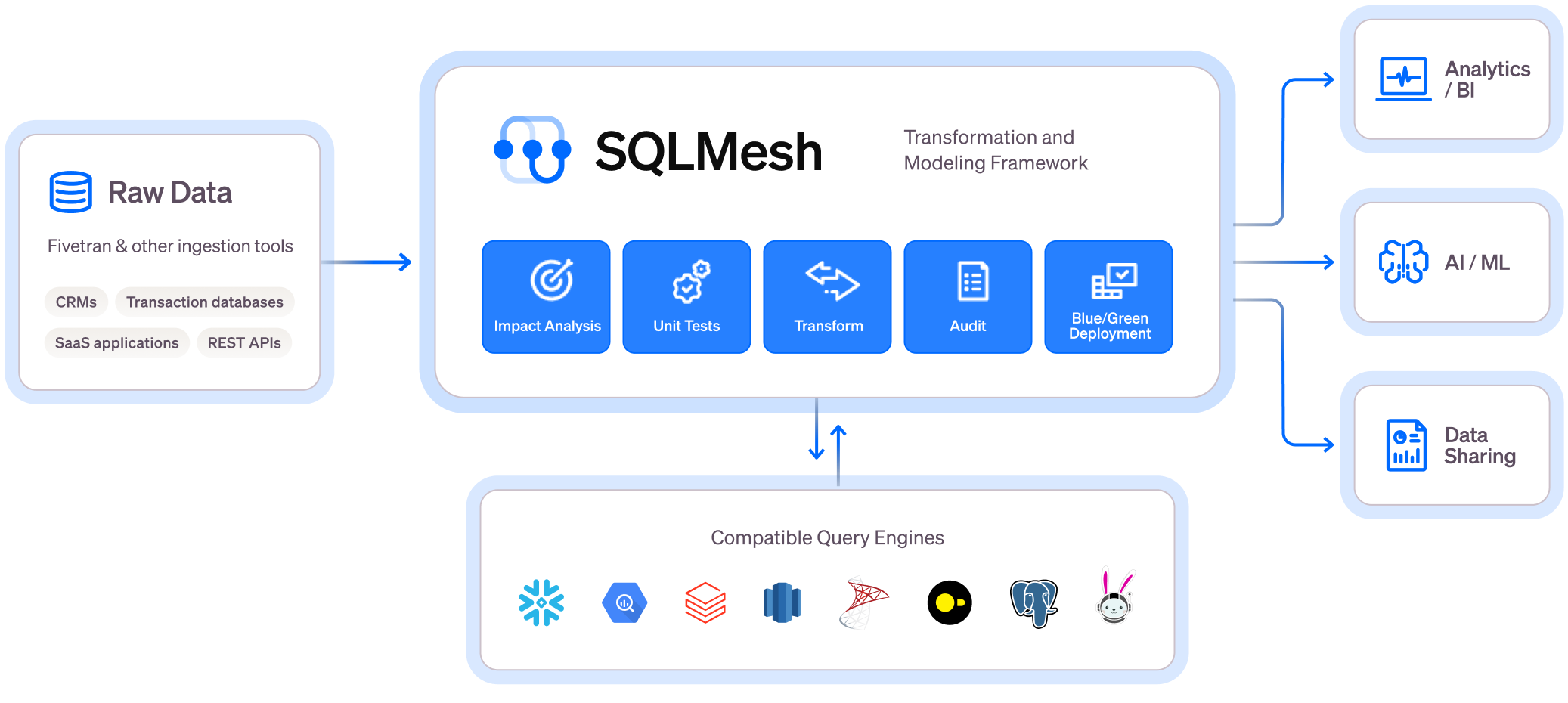
Best for: Data engineers seeking fine-grained control over SQL pipelines.
SQLMesh applies a software engineering approach to transformations, using Python-based configuration, environment isolation, and incremental rebuilds.
Key Features:
- Automatic change detection to rebuild only affected models
- Environment management for staging/production
- Open-source and cloud-ready
- Appeals to developer-heavy teams
Potential Drawbacks:
- New ecosystem: Still maturing, with limited community and tooling compared to more established vendors.
- Developer-centric: Requires Python and SQL knowledge for configuration.
8. dbtThe open-source ELT |
Best for: Analytics engineers looking to apply software engineering practices to SQL pipelines.
dbt introduced the concept of “analytics engineering,” adding version control, testing, and modular design to SQL transformations. It’s available as an open-source CLI and as dbt Cloud, which offers a managed interface and scheduling.
Key Features:
- Modular SQL models with dependency management
- Built-in testing and documentation
- Large community and integration ecosystem
- Flexible deployment options (self-hosted or managed)
Potential Drawbacks:
- CLI-centric: Limited visual interface; less approachable for non-technical users.
- Technical & troubleshooting complexity: Deep dependency graphs can make debugging difficult. Steep learning curve and technical hurdles that only seasoned engineers are likely to tolerate.
- Structural organization and standardization: You will need strong processes, documentation habits, naming conventions, and senior engineers to keep things in check.
 |
9. WhereScapeData warehouse Automation |
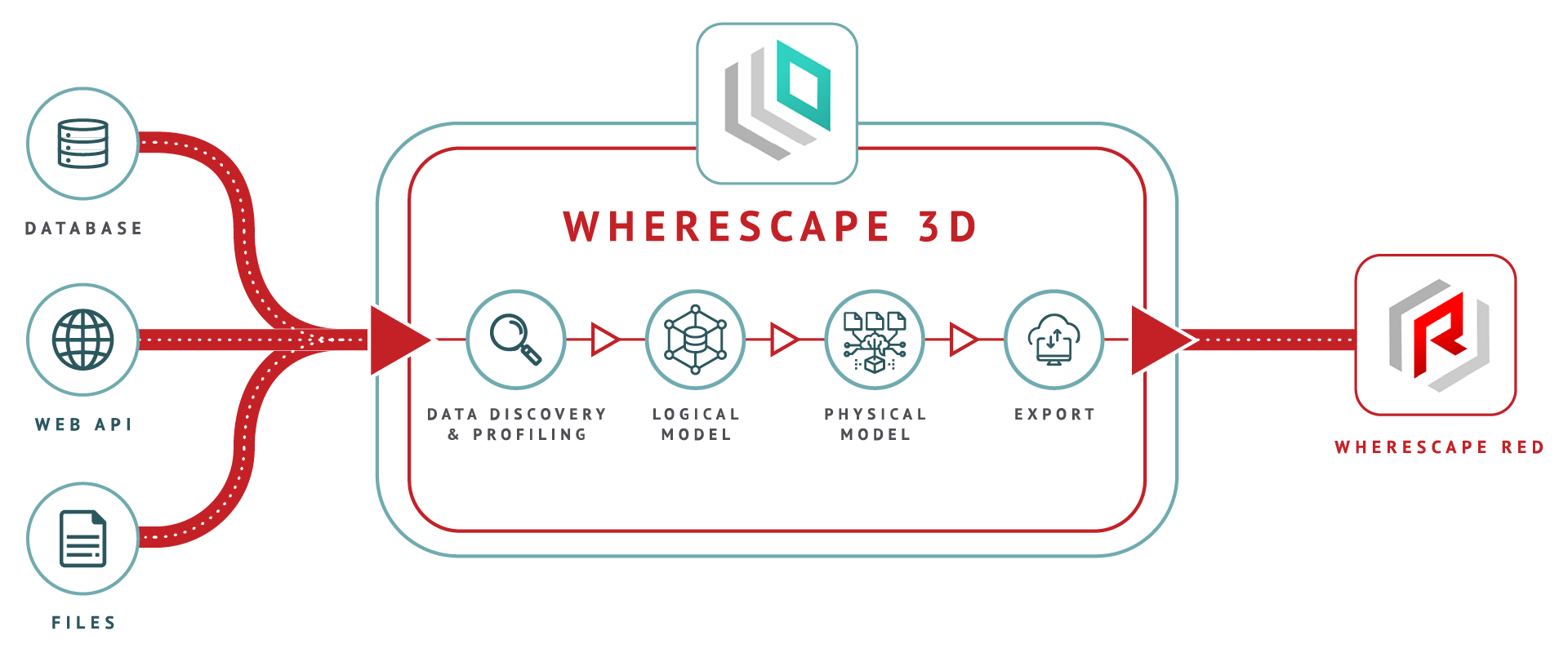
Best for: Enterprises needing rapid warehouse prototyping and automation.
WhereScape’s automation tools (RED and 3D) auto-generate schemas, transformation code, and documentation based on metadata-driven design.
Key features:
- Automated schema and code generation
- Supports cloud and legacy databases
- Strong in highly governed, traditional enterprise environments
Potential Drawbacks:
- Limited flexibility: Auto-generated schemas may need significant customization.
- Legacy focus: Oriented toward traditional enterprise, less suited for cloud-native setups.
 |
10. Apache BeamUnified batch and stream processing |
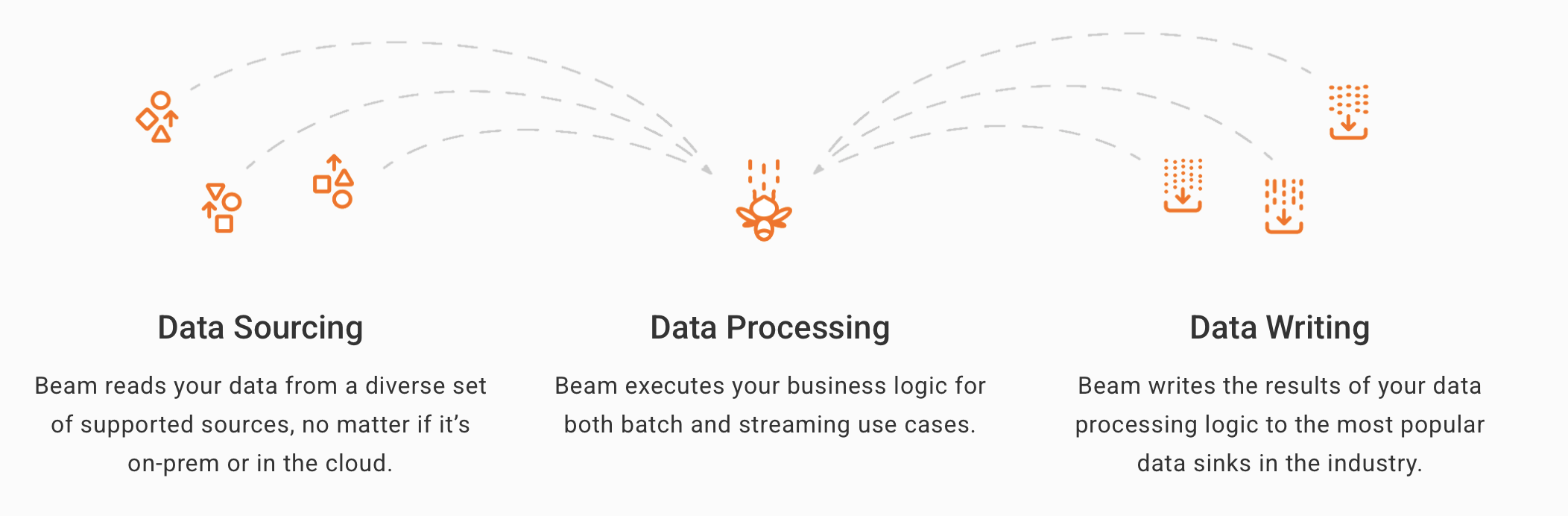
Best for: Engineering-heavy teams building custom batch/stream pipelines.
Beam offers a unified programming model for batch and streaming data, running on multiple runners (Google Dataflow, Flink, Spark).
Key Features:
- Language support for Java, Python, Go
- Cross-runner portability
- Strong for real-time and event-driven use cases
Potential Drawbacks:
- Engineering-heavy: Requires deep knowledge of distributed processing frameworks.
- Governance gap: Provides raw processing capabilities without built-in governance or documentation features.
Frequently Asked Questions
It’s used to clean, join, and reshape raw data into analytics-ready formats—often within a cloud data warehouse or lakehouse.
Data engineers, analytics engineers, BI developers, and sometimes analysts use them to standardize and automate data prep.
For small workloads, BI tools’ modeling layers may suffice. But for scale, governance, testing, and CI/CD, a dedicated transformation tool is essential.
Yes—while these platforms offer built-in transformation capabilities, they’re not purpose-built for designing, automating, and governing complex pipelines at scale. A dedicated transformation tool adds features like visual modeling, version control, environment management, testing, and automation that make development faster, safer, and more collaborative. It also helps you apply consistent best practices across teams, regardless of the underlying platform, and future-proofs your workflows if you adopt a multi-platform architecture.