Key Takeaways
A data catalog helps you find, understand, and trust your data fast. Whether you’re dealing with fragmented data across tools or struggling with poor documentation, the right data catalog tools can centralize metadata, surface lineage, and improve governance at scale. In this guide, we compare 10 of the best data catalog tools of 2025, including modern AI-powered solutions and open-source favorites.
What is a data catalog?
Think of data catalog tools like a library card catalog—only for your company’s data. Instead of listing books, it indexes datasets, metrics, dashboards, and lineage, so users can find and understand data faster. A good catalog doesn’t just tell you what data you have and where it lives—it also explains how it’s used, who owns it, and whether it can be trusted.
Modern data catalogs go far beyond basic metadata indexing. They now leverage AI to auto-document assets, surface column-level lineage, classify sensitive data for governance, and even flag issues like schema drift or data quality anomalies. Whether you’re a data engineer, analyst, or business stakeholder, data catalogs have become foundational for collaboration, compliance, and scalable data use in today’s complex data environments.
Why use a data catalog in 2025?
The explosion of tools in the modern data stack—Snowflake, Databricks, Fivetran, Sigma, and beyond—has created both opportunity and complexity. With data assets multiplying across teams and platforms, organizations face:
- Data silos that limit discoverability
- Inconsistent definitions that lead to reporting errors
- Manual documentation debt that slows development
- Unclear ownership that hampers governance
Data catalogs solve these problems by bringing structure, visibility, and trust to your data. In 2025, most leading platforms use AI to scale documentation, reduce manual work, and enable dynamic lineage views.
In this post, we explore 10 of the best data catalog tools in 2025—including open-source solutions, enterprise-grade platforms, and next-gen AI-powered catalogs transforming how teams discover and govern data. We’ve chosen the catalogs that came up most frequently during our research—those that are widely recognized across the industry for their popularity and brand visibility. While somewhat subjective, this approach reflects what many data teams are actually evaluating or using today.
What are the best data catalog tools of 2025?
1. Coalesce CatalogThe only catalog built into a transformation platform |
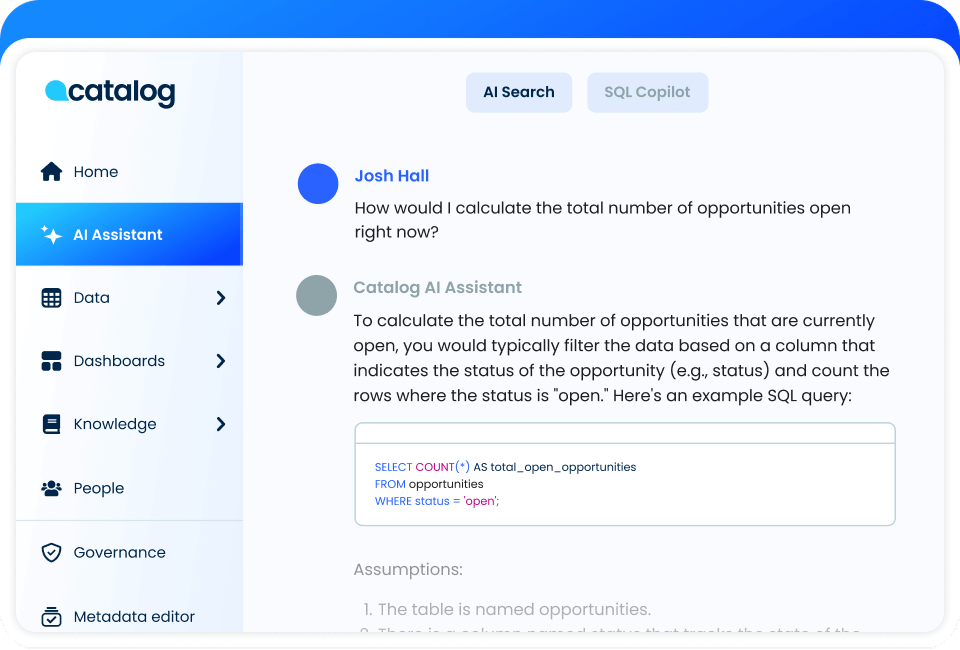
Best for: Modern data teams at scale that need real-time documentation, AI assisted discoverability, and embedded governance-without the sprawl or manual effort.
Launched in 2023, Coalesce Catalog delivers a next-generation experience for data documentation and discovery, fully embedded in the Coalesce platform. Unlike legacy tools or bolt-on solutions, Coalesce treats documentation as a live artifact of the transformation process-not a disconnected afterthought.
With automatic updates as you build, every object and column becomes instantly searchable, explainable, and governed-ready for AI, audits, and analytics.
Key strengths:
- Real-Time Lineage: Auto-generated, column-level lineage for full transparency and easy impact analysis
- AI-Powered Discoverability: Use natural language to search for assets relevant to your role, project, or domain—no technical expertise required
- AI-Powered Metadata: Suggested descriptions and enrichment through Coalesce Copilot
- Built-In Governance: Role-based access controls and audit-friendly metadata baked in
- Multi-Cloud Support: Catalog works across Snowflake, Databricks, Microsoft Fabric, and more
Why it matters in 2025
Many teams using Matillion, Talend, Informatica, or drag-and-drop tools face a harsh reality: documentation is manual, governance is reactive, and scaling is painful.
Coalesce Catalog flips that script with:
- A single interface to build, document, and govern data
- Always-on AI assistance, not just for code but for metadata and context
- A catalog that is up to date on the objects you care about, not lagging behind development
With Coalesce, governance is built in from day one.
👉 Request a custom demo or take a virtual product tour to see how Coalesce replaces complexity with speed, governance, and clarity.
💰 You can also request pricing here.
2. Collibra Data CatalogComplex data governance |
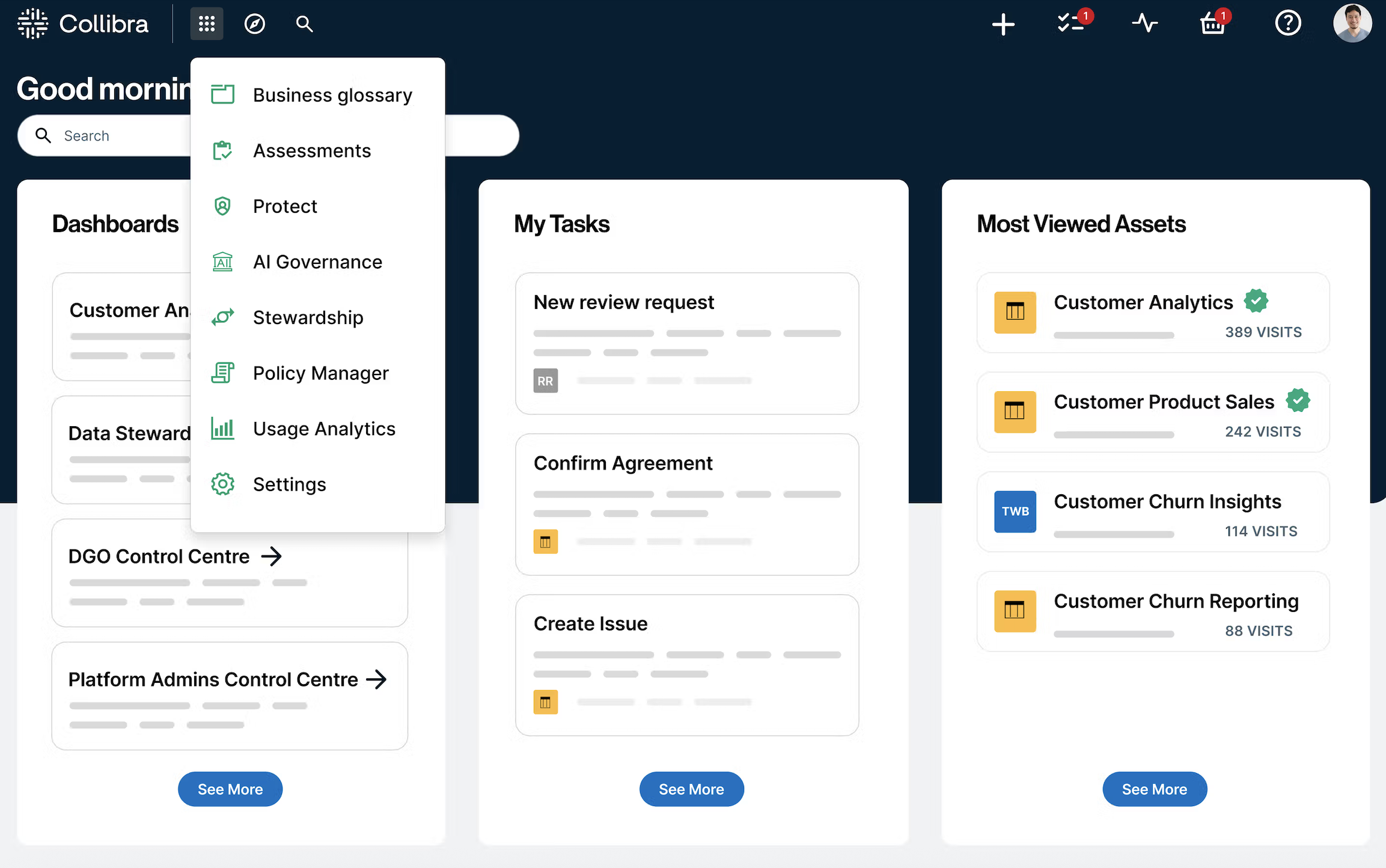
Best for: Large organizations with complex governance needs
Collibra has been in data governance since 2008. Its catalog supports enterprise-scale metadata management, policy enforcement, and AI-based data discovery across thousands of data sources.
Highlights:
- Role-based access policies and certification workflows
- Machine learning for metadata classification
- Tight alignment with data governance frameworks
Collibra remains a go-to for financial institutions, healthcare systems, and other heavily regulated industries.
3. Alation Data CatalogAgentic Data Intelligence Platform |
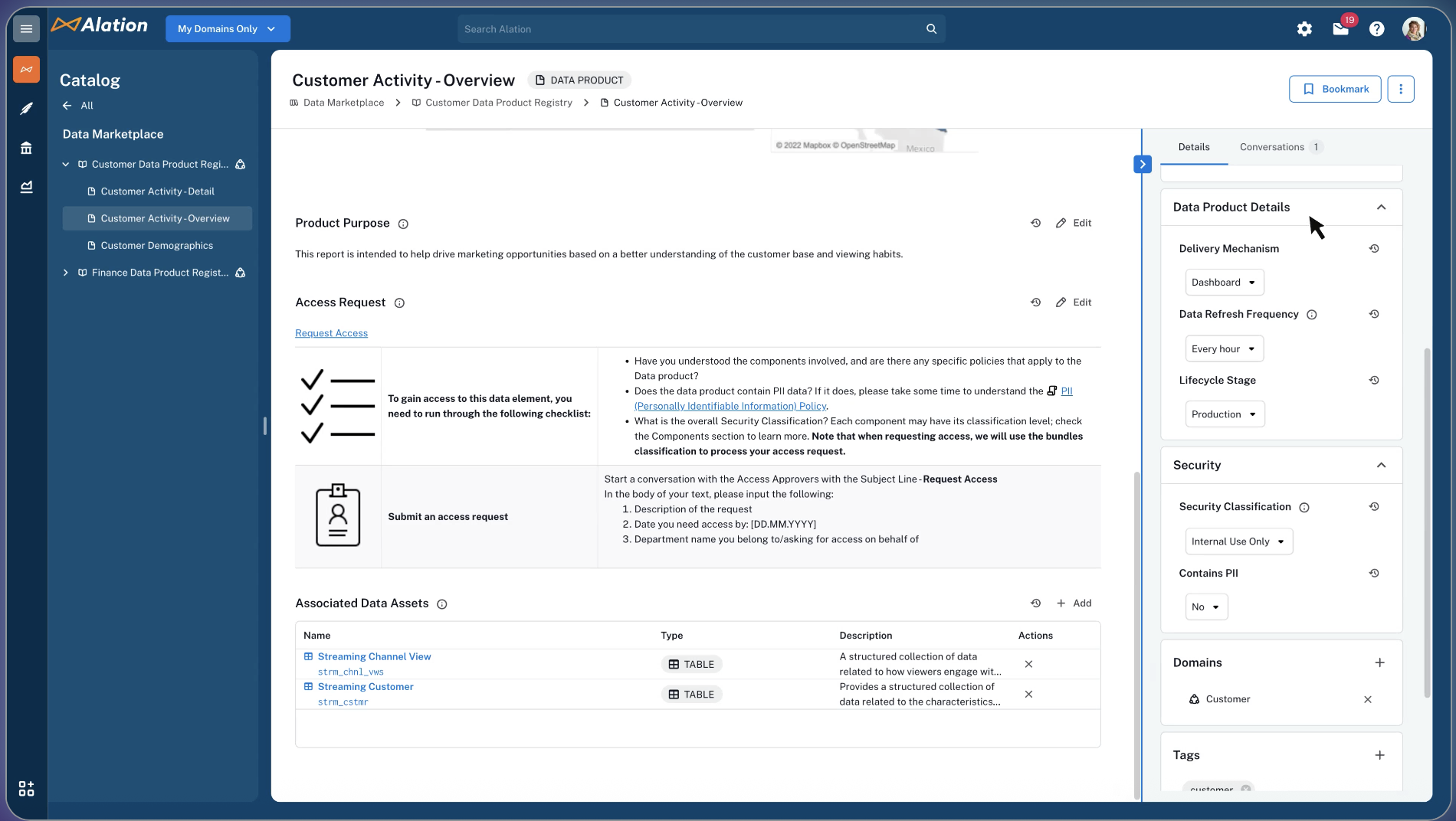
Best for: Democratizing data access through collaborative workflows
Founded in 2012, Alation helped define what a modern data catalog looks like. Today, it combines AI-powered suggestions, an intuitive UI, and collaborative features that scale from analysts to stewards.
What stands out:
- “Allie,” the in-product AI assistant for documentation
- Popularity scoring for queries and datasets
- Built-in governance apps and policy tools
- Rich integrations with BI and query tools
It’s widely adopted for fostering data literacy and self-service analytics across large orgs.
4. AtlanCollaborative data workspace |
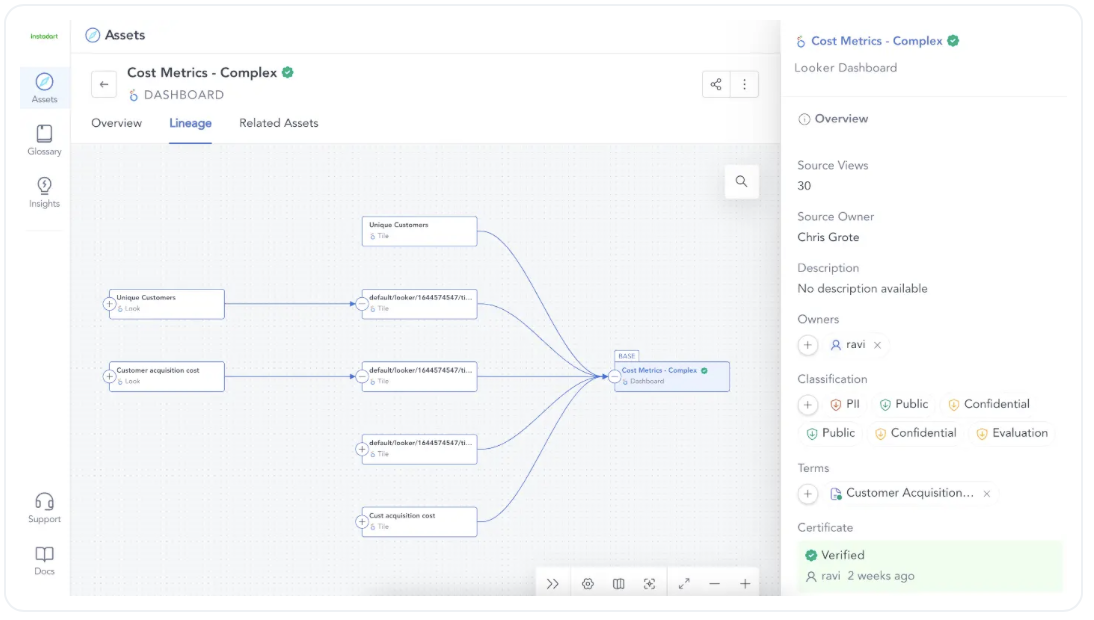
Best for: Data teams prioritizing active metadata, collaboration, and ease of adoption.
Overview:
Atlan positions itself as a modern data workspace designed to improve collaboration across data, engineering, and business teams. Its catalog is centered around usability and automation, aiming to embed metadata into daily workflows rather than treating it as a passive documentation layer.
Key features:
- Active metadata with real-time syncing across tools and pipelines
- In-workflow collaboration via Jira, Slack, and Microsoft Teams integrations
- Data ownership and discovery tools including tagging, glossary management, and personas
- Open architecture, with APIs and SDKs for custom integrations and extensibility
Atlan is often favored by organizations looking to increase adoption of their data catalog by embedding it into the existing tools and routines of their users.
5. InformaticaData management cloud |
Best for: Legacy enterprises already using Informatica
A veteran in the data space, Informatica offers deep scanning and profiling across hybrid environments. Its catalog shines in organizations using Informatica for ETL, data quality, or MDM.
Key Features:
- Automated data profiling at scale
- End-to-end lineage visualization
- Integration with data quality and privacy tools
- Support for Hadoop, cloud, and on-prem assets
While less modern in interface, it has an extensive breadth of metadata coverage.
 |
6. Acryl DatahubOpen-source data management platform |
Best for: Engineering-led teams that want flexibility and extensibility
Acryl commercializes the popular DataHub open-source project from LinkedIn. It uses a graph-based model to connect data assets and surface lineage and impact.
Key Features:
- Open source, extensible, and cloud-ready
- Rich metadata APIs and developer tooling
- Real-time metadata ingestion
- Strong community and documentation
It’s the ideal choice for data teams that want full control and developer-first infrastructure.
 |
7. AmundsenLightweight open-source discovery |
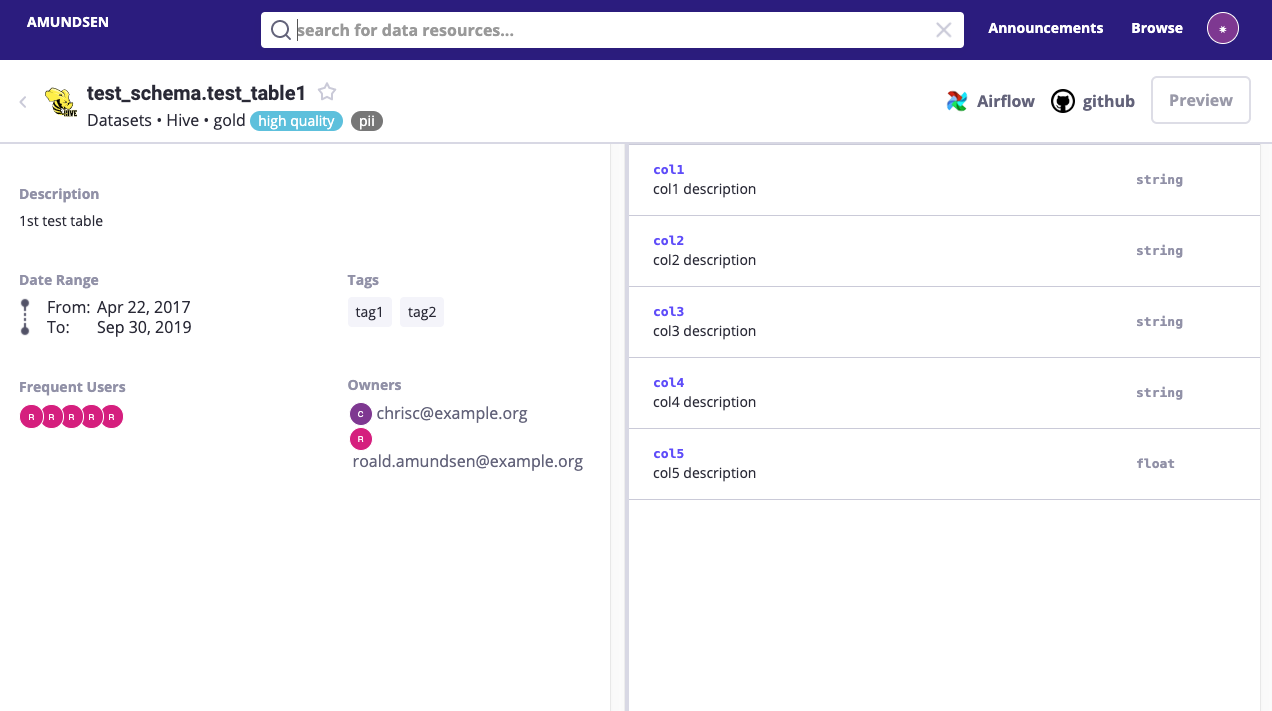
Best for: Startups and small teams needing quick data discovery
Developed by Lyft, Amundsen offers a minimalist approach to cataloging, focusing on search relevance and simplicity. It’s widely used in engineering orgs and has multiple managed service variants.
Key Features:
- Fast search with PageRank-inspired ranking
- Light integration footprint
- Indexes tables, dashboards, and users
- Active open-source community
Perfect for teams that need a free, no-frills solution with strong search.
8. Microsoft PurviewAzure-native governance |
Best for: Organizations operating primarily on Azure
Microsoft Purview brings cataloging, governance, and compliance into a single pane of glass for the Azure ecosystem. It auto-scans Azure resources and offers AI-driven search and lineage.
Key capabilities:
- Integration with Power BI, Synapse, and Azure Data Lake
- Automated classification and sensitivity labels
- Business glossary and role-based access
- Native compliance workflows
A must-have for Azure-centric enterprises.
9. Select StarSimple data catalog |
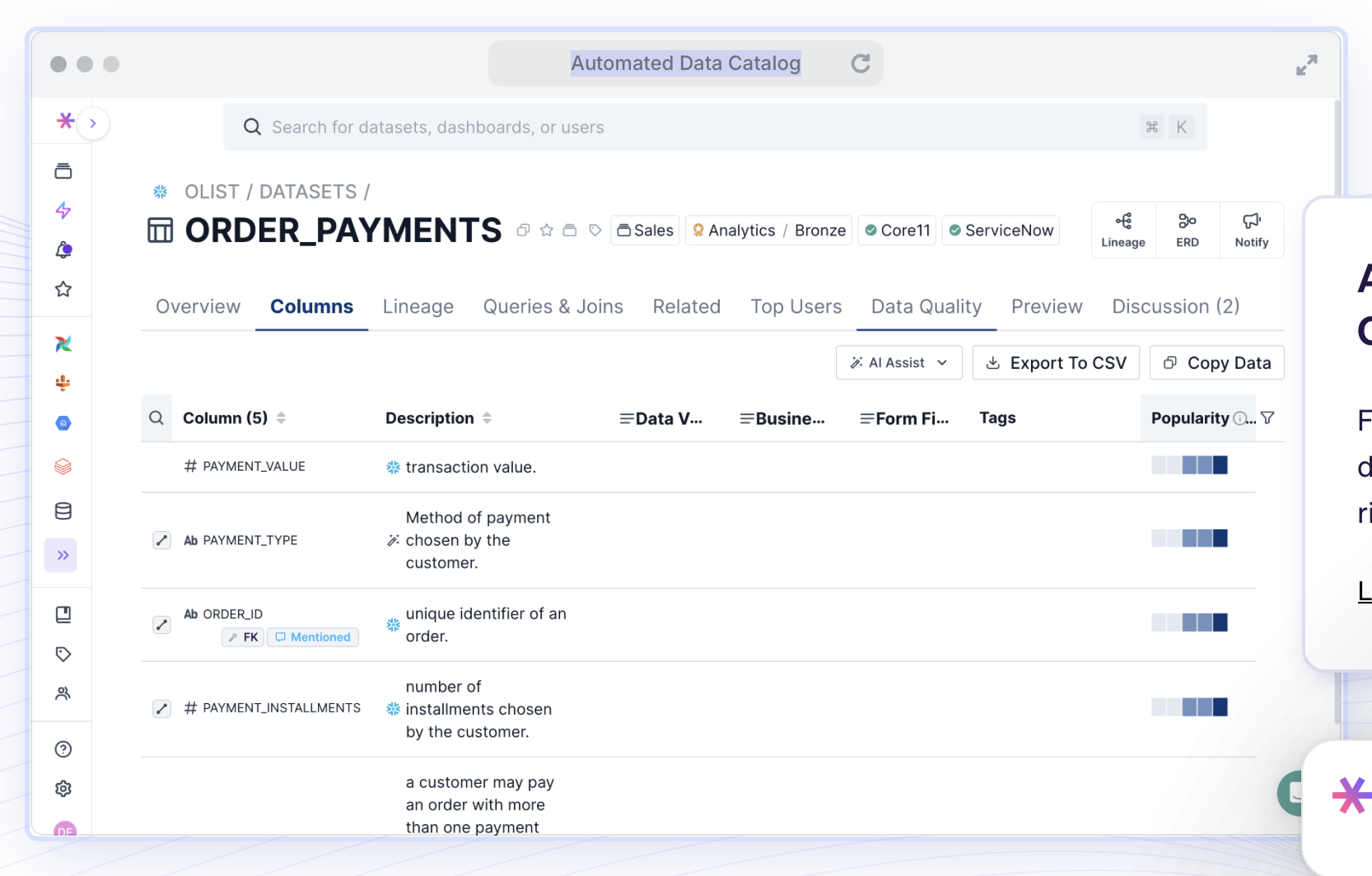
Best for: Teams seeking fast setup and smart suggestions
Select Star emphasizes ease of use with automatic documentation, built-in lineage, and intelligent popularity tracking. Its UI is designed for business users and analysts as much as engineers.
Key features:
- Column-level lineage and popularity insights
- Auto-generated documentation
- BI tool and warehouse integrations
- Out-of-the-box dashboards
- New MCP server for managing metrics and policies at scale
Great for teams starting fresh with modern infrastructure.
 |
10. Data.worldKnowledge graph-driven catalog |
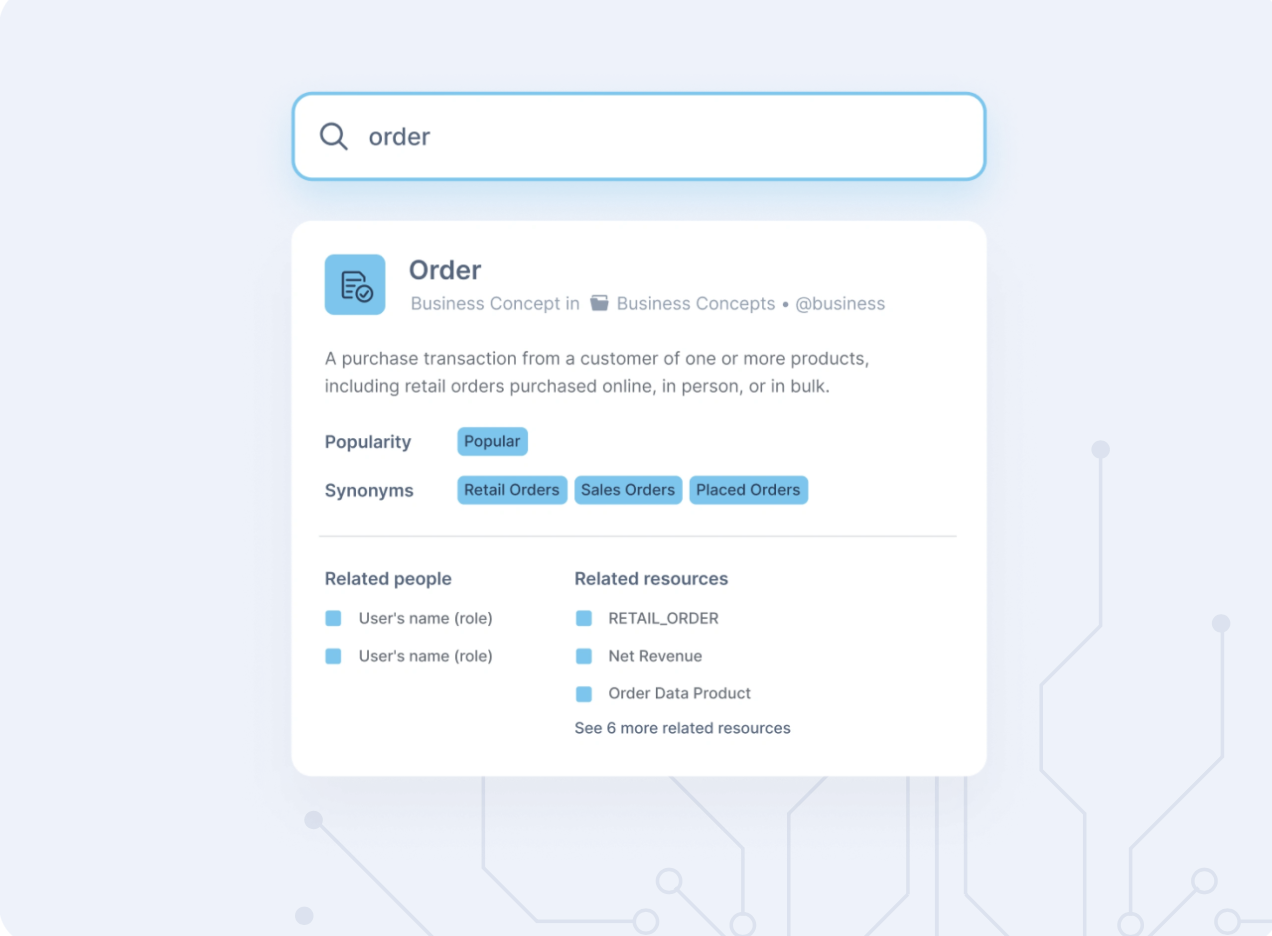
Best for: Semantic search and cross-domain collaboration
data.world applies knowledge graph principles to metadata. It connects assets across systems, adds semantic context, and supports rich relationships—ideal for data discovery across silos.
Advantages:
- Graph-based search and relationship modeling
- Collaboration via discussions and “data projects”
- Bots for automated enrichment
- Friendly to both data and non-data users
Especially valuable for large companies focused on data culture and literacy.
Ready to Build a Catalog That Works With Your Transformations?
Choosing the right catalog is just the start. If you’re managing complex data pipelines and want your documentation and governance to keep up in real time, consider a catalog that’s natively integrated with your transformation layer.
With Coalesce Catalog, your lineage, documentation, and ownership are automatically updated every time you transform data—eliminating manual steps and ensuring trust across your stack.
Frequently Asked Questions
A data catalog is used to organize and centralize metadata about your data assets—like datasets, dashboards, and metrics—so teams can easily discover, trust, and govern their data.
Data engineers, analysts, stewards, compliance teams, and even business users use data catalogs to find data, understand it, and ensure it’s being used responsibly.
A data catalog indexes and documents your data assets, while a governance tool enforces rules around access, compliance, and quality. Many modern data catalogs (like Coalesce) include governance features.
Not necessarily—but you’ll likely benefit from one. While you can absolutely use Snowflake, Databricks or Microsoft Fabric without a catalog, it doesn’t automatically provide visibility into things like lineage, ownership, documentation, or data trust. A data catalog complements Snowflake, Databricks or Fabric by adding that missing layer of context, making it easier for teams to discover, understand, and confidently use the data already at their fingertips.
Select Star and Amundsen are great for small teams or startups, thanks to their ease of use and minimal setup. Acryl DataHub is also a strong open-source option for more technical teams.