The goal of modern ETL (extract, transform, load) tools is to simplify the transformation process of turning raw data into clean, usable information. At the surface level, these tools seem to solve this problem and more. Many offer visual interfaces or simplified coding frameworks that accelerate development and deliver quick wins. Yet, as pipelines grow and teams scale, new layers of complexity emerge. What seemed like a time-saving solution can quietly accumulate costs that undercut its value.
At first glance, it may seem like the biggest risks are infrastructure or licensing costs. But the real drain often isn’t in your cloud bill—it’s on your payroll. These tools may reduce the hard costs, the ones you can forecast, like subscription fees or compute spend. But they often introduce soft costs that are harder to see: engineering hours, coordination overhead, delays, and inefficiencies that quietly add up as your pipelines grow. These are the human costs of complexity, and they’re the ones most likely to balloon at scale.
For data engineers and leaders, understanding these pitfalls early on can prevent frustration later. Below, we break down the most common hidden costs tied to the transformation layer. While we use ETL throughout the article for simplicity, this primarily refers to data transformation tools that follow the more common ELT (extract, load, transform) pattern used in modern data stacks.
Version confusion: The merge conflicts no one talks about
Few ETL tools are built for collaboration. While they might work fine for solo development, they often break down once multiple people need to contribute. Git support is either bolted on or missing entirely. Pipelines get exported as giant XML or JSON blobs that are difficult to diff, merge, or review.

Without precise version control, even fundamental team workflows become complicated. There’s no easy way to roll back changes, run peer reviews, or isolate development branches. Mistakes snowball, and fixes take longer than they should. Over time, teams may limit access to only a few trusted users. That bottleneck slows down development and raises the stakes for every change.
This challenge compounds when organizations grow and data projects expand. Without clean version history, teams often waste hours recreating work that’s already been done. And when audits or compliance reviews inevitably occur, the lack of traceable changes and approvals makes it difficult to explain what happened and why.
Even worse, without tooling that supports proper diffs and context-aware reviews, it’s easy to miss subtle but critical changes. Transformation logic often contains the nuances that determine business outcomes. A single filter or join change might radically alter KPIs. Without version-aware tooling, those changes slip by unnoticed until the damage is done.
Duplicate effort from limited reusability
Some ETL tools don’t make it easy to reuse transformations. Without templates or modular design, logic is copied and pasted across pipelines. Every small change becomes a tedious hunt for where that logic resides. When you miss a spot, your outputs become inconsistent.
This duplication is the beginning of technical debt. As the number of jobs increases, the structure becomes brittle and difficult to navigate. Engineers spend more time managing repeated logic than building new products for the business. A platform that doesn’t prioritize reusability adds friction to every future update.
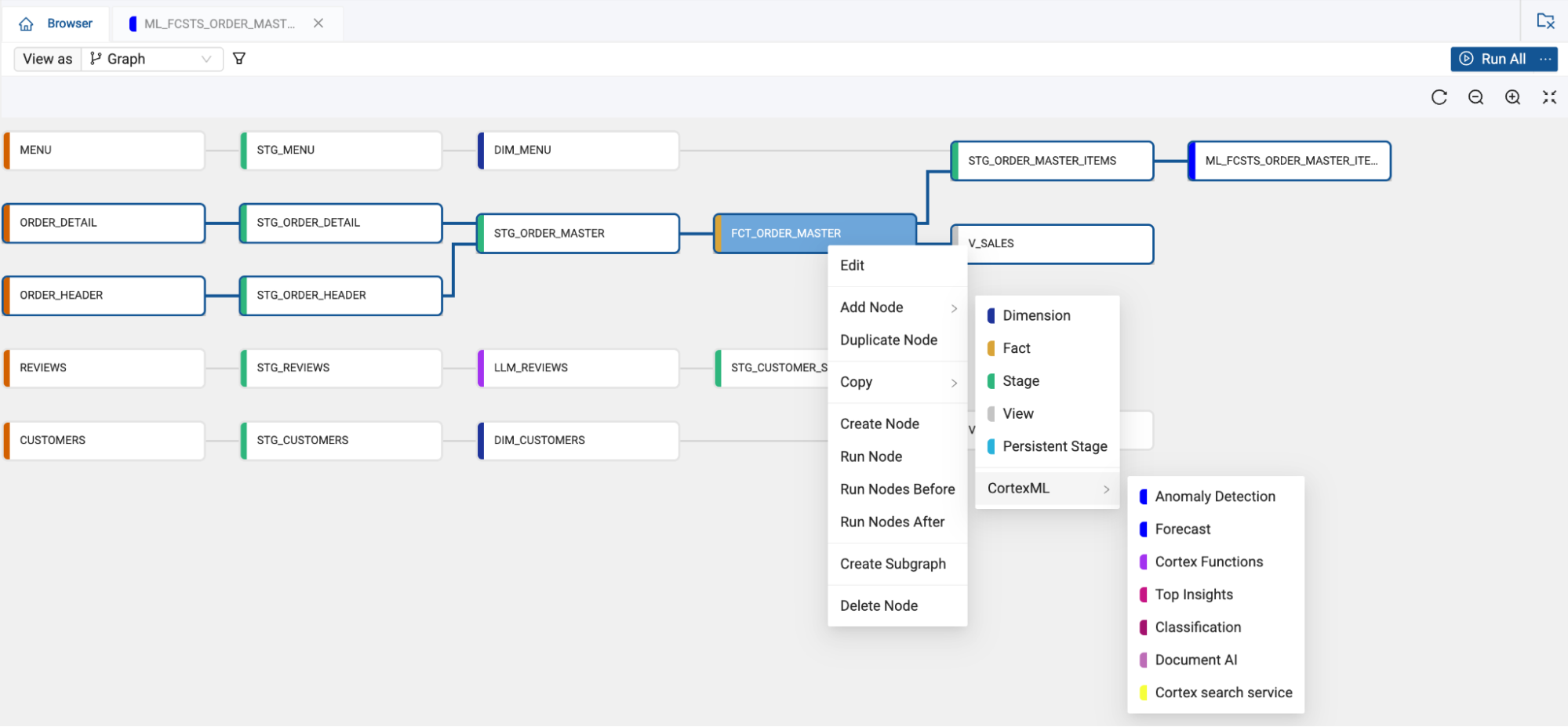
Over time, the cost of this redundancy grows. Logic updates become risky. Teams hesitate to make improvements because the blast radius is unclear. The result? A stagnating data platform where the fear of unintended side effects blocks innovation. Teams end up solving the same problem multiple times, often with slightly different approaches that erode trust in the results.
A platform that doesn’t prioritize reusability adds friction to every future update.
Debugging in the dark: ETL error unknown
When something breaks, debugging should be quick; however, in many ETL systems, error messages are vague and logs are hard to access. The simplicity that made building easy now works against you.
Finding the root cause becomes a slow, manual process. Is it the data source? The transformation logic? A typo in a formula? Without lineage or clear traceability, engineers waste time playing detective. Meanwhile, dashboards stall, decisions wait, and frustration builds across the organization.
Without lineage or clear traceability, engineers waste time playing detective.
The stakes are exceptionally high when pipelines support customer-facing dashboards or executive reporting. An ambiguous error message or lack of visibility can delay decisions, inflate data team workloads, and lead to distrust in the analytics function as a whole.
Taking it a step further, the root cause might be invisible without multiple hours of investigation. With highly abstracted tools, developers might not even know where the data is being processed. Is it in the cloud warehouse, in-memory, or across distributed systems? This makes optimizations and troubleshooting nearly impossible.
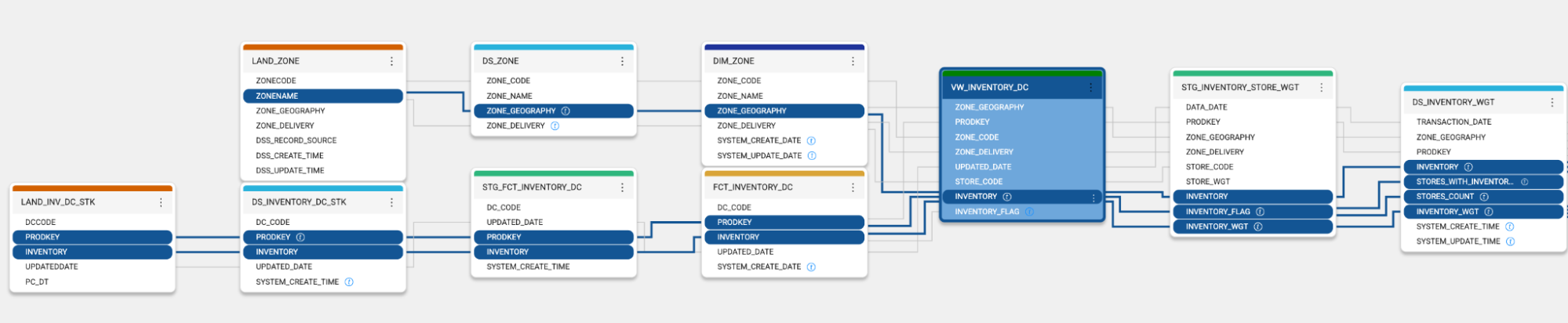
Debugging is often exacerbated by tools that don’t surface intermediate outputs. Without being able to inspect the data at each transformation step, engineers must make assumptions. They may resort to building temporary audit tables or re-running jobs with added logging, which increases turnaround time, introduces new errors, and puts strain on the underlying infrastructure.
A lack of observability also impacts team communication. Engineers can’t easily show others where something went wrong. Cross-functional teams struggle to triage issues without access to data snapshots or logs. What should be a five-minute conversation becomes a two-day investigation.
Silent failures, loud consequences
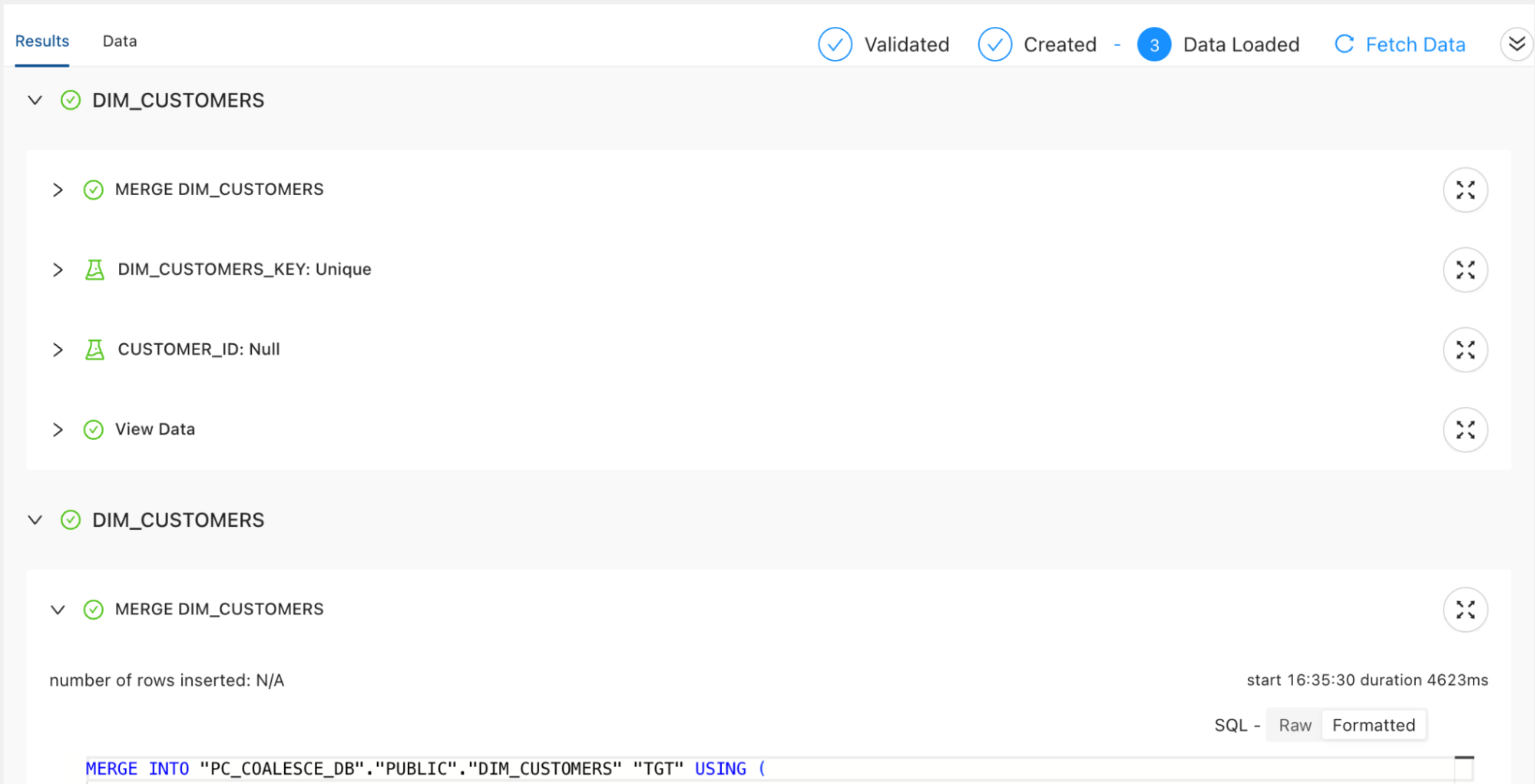
ETL pipelines need testing just as any software system does. But too often, transformation tools lack sufficient support for data validation. There’s no way to write tests against transformation outputs, no staging environments, and no CI/CD.
This opens the door to silent errors. A small change to logic might drop rows or misclassify categories, and no one notices until it’s too late. Trust suddenly erodes with your team. People resort to manual and ad hoc analysis. Fixing the problem requires both time and a culture shift toward defensive engineering.
The absence of automated testing creates downstream risk as well. Analysts must second-guess pipeline output, executives lose faith in reporting, and every deployment becomes a gamble. Over time, this leads to cautious, slow-moving data teams that can’t keep pace with the business.
ETL testing also includes schema checks, data type consistency, and null value handling. Without built-in tools to validate these components before a pipeline runs, changes are deployed in the dark, increasing the risk that teams won’t catch issues until something breaks.
Testing should also extend to row-level expectations, aggregate validations, and dependency checks. Does the transformation always return a non-null value for a key column? Are row counts what we expect compared to the source? Are lookups resolving correctly? Without assertions built into the pipeline, there’s no safety net.
In modern data engineering practices, pipelines should ship with tests just like application code. These tests allow pipelines to evolve safely. But if your ETL tool doesn’t support automated checks, or if tests live outside the pipeline altogether, they often don’t get written. The cost to your business? Increased fear of change, slower releases, and firefighting when things break in production. This reactive posture limits team velocity and consumes valuable hours that engineers could spend solving real (not self-inflicted) business problems.
Cloud bill roulette: The scalability cliff you didn’t see coming
As data volumes grow, performance issues surface with most ETL pipelines. Some tools don’t push down SQL efficiently or require full table scans on every run. Others abstract execution so much that you can’t optimize what’s slow. Eventually, you hit a tipping point where something needs to change. Jobs are taking too long, cloud bills spike, and teams need to rebuild large portions of the pipeline to stay afloat. Poor scalability doesn’t just add cost; it reduces agility when the business needs fresh insights fast.
As data sources multiply and data freshness becomes a competitive advantage, performance becomes critical. Slow pipelines can mean lost opportunities or lagging customer insights. The inability to optimize or control performance at scale turns into a strategic disadvantage.
Data teams may also struggle with limited visibility into query performance, concurrency bottlenecks, or inefficient join logic. If engineers can’t tune transformation logic, they’re left with brute-force workarounds or costly infrastructure overprovisioning.
Poor scalability doesn’t just add cost; it reduces agility when the business needs fresh insights fast.
Vendor lock-in: It’s a feature, not a bug
At the end of the day, we all want transformation logic to be portable. But in many ETL tools, it’s locked into proprietary formats. You can’t export it cleanly, integrate it with new tools, or refactor it without rewriting from scratch.
This rigidity becomes a problem when your organization evolves. If you want to adopt a new warehouse or add a real-time pipeline, your existing transformations might not translate. What was once a quick solution is now a barrier preventing progress, the cost of which only increases over time.
Lock-in also makes it harder to evaluate alternative platforms or adopt emerging best practices. You’re limited to the capabilities a vendor prioritizes. Their decisions narrow your options and increase dependency on external roadmaps that may not align with your strategy.
Teams hoping to modernize their stack often find that legacy pipelines are challenging to migrate, not due to data size or schema complexity, but because the transformation layer is deeply entangled within an inflexible platform. This dependency leads to significant opportunity cost, as data teams miss out on modernizing their data stack and spend time translating all that logic if they choose to migrate.
Friendly UIs, frustrated teams
The user-friendliness of a tool doesn’t always mean it’s team-friendly. If a visual tool limits precision, engineers might avoid it. If it requires heavy coding, analysts may be locked out. A mismatch between tool and team creates bottlenecks. Pipeline ownership burns out engineers, while analysts wait on slow turnaround times—all while critical knowledge lives in one person’s head. In the long run, the tool that seemed accessible might hamper productivity instead of improving it.
This fragmentation creates hidden costs in onboarding, support, and cross-functional collaboration. The tool that promises democratization may unintentionally silo teams further by excluding those who don’t speak its language. When engineers avoid a tool out of frustration, or analysts defer to others for basic tasks, the system becomes less self-service, not more. This gap in autonomy forces teams into inefficient workflows that scale poorly.
The user-friendliness of a tool doesn’t always mean it’s team-friendly.
Black box pipelines, white knuckle reviews
Transformation logic is often where data meaning lives. But without documentation and lineage, that meaning disappears. If someone leaves the team, or if a stakeholder asks where a number came from, there’s no easy way to trace the answer. Pipelines become black boxes and mistakes take longer to find. Whenever there are changes, they come with increased risk.
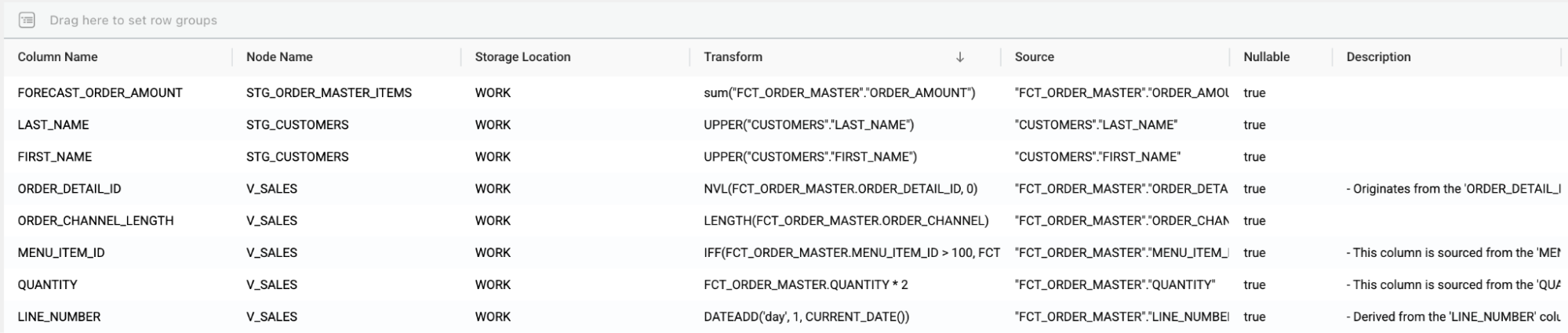
The best tools capture lineage and metadata automatically. Poor tools require manual documentation, which rarely gets done. The cost isn’t just time, but confidence. In highly regulated environments or complex enterprises, a lack of lineage and documentation can have compliance implications. It also slows down audits, makes training harder, and increases reliance on a shrinking pool of tribal knowledge.
Go from firefighting to future-proofing
The good news is these costs are avoidable. The right platform can embed best practices into the development process without adding friction. Reusable templates, modular design, built-in testing, and version control all help teams scale cleanly. Features like column-level lineage and automated documentation remove guesswork.
Coalesce is a platform built to handle these challenges. It brings together a flexible interface, a standardized approach, and developer-first workflows. With Coalesce, teams can build quickly, collaborate confidently, and maintain transparency at scale.
But more than a tool, what matters is a mindset. If you treat pipelines like products, design for change, document as you build, and choose proper tooling, those habits become proactive, not reactive. That’s how you keep transformation fast, reliable, and cost-effective—not just from the outset, but for the long term.
Try it for yourself
To experience the power of Coalesce, take a virtual product tour or sign up for a free 14-day trial.