Today’s data teams face a dual challenge: accelerate data pipeline engineering while maintaining enterprise-grade control. As data volumes grow and complexity increases, tools that support both speed and scalability become essential. Coalesce addresses this need as a data engineering platform that optimizes developer efficiency and emphasizes maintainability.
While Coalesce is known for its intuitive graphical user interface (GUI), it is much more than a point-and-click tool. Under the hood, Coalesce provides developer tools for data engineering, enabling teams to build production-grade ELT pipelines using automation, version control, parameterization, architectural standards, and SQL-based logic.
Its modular data transformation architecture supports both rapid prototyping and sustainable, long-term scalability. This dual interface and deep customization make Coalesce a leading choice for teams looking to modernize and standardize data engineering workflows.
Dual interface: Visual simplicity meets full-code power
A hybrid platform for analysts and engineers
Coalesce operates on a flexible interface that unites visual data transformation with the full flexibility of code. This unified approach enables teams to build data pipelines with consistent development practices while retaining access to raw SQL, YAML configurations, and Jinja templates for complete control. Analysts and data stewards can build and iterate quickly within organizational standards, while engineers can implement business logic while fully managing data governance, performance, and extensibility.
Integrated tools for the modern developer
Beyond the GUI, Coalesce integrates natively with Git for version control and supports automated deployments through its command-line interface (coa). Engineers can connect pipelines to CI/CD workflows, enabling rapid iteration without compromising stability. Developers can use Git branching, commits, and pull requests to manage transformation logic and other changes within a project.

Combined with support for reusable templates and metadata-driven configurations, Coalesce provides a flexible, extensible framework that fits into modern data engineering patterns. Reusable templates in Coalesce allow developers to define common transformation logic once—such as standard cleansing steps or business rules—and apply it across multiple pipelines using dynamic parameters. These templates, built with Jinja and YAML, reduce duplication, enforce consistency, and speed up development by turning repeatable logic into easily maintained building blocks.
Nodes as functions: Applying software engineering principles
Building pipelines like programs
In Coalesce, every data pipeline is structured as a Directed Acyclic Graph (DAG). Each node in the DAG represents a logical block of transformation logic—similar to a function in a traditional software program. These nodes can encapsulate specific logic, such as filtering, joining, or deduplicating data, and are designed to be modular and reusable. Pipelines themselves behave like programs, composed of functions that follow defined dependencies and execute in sequence.
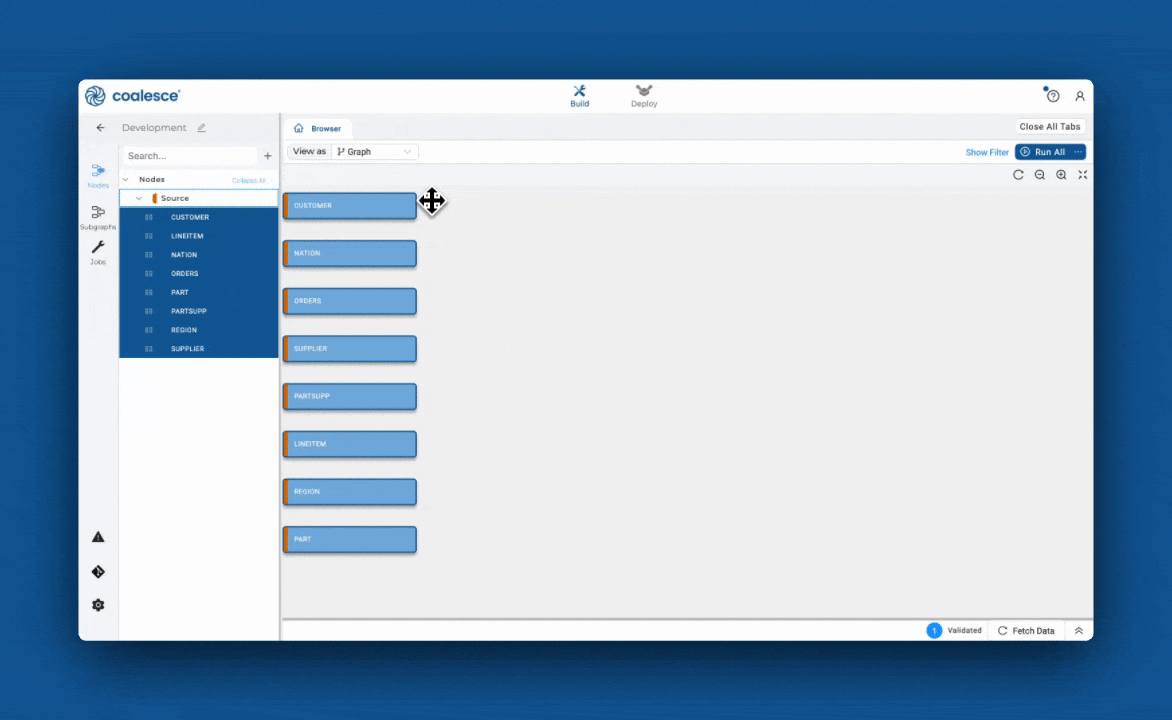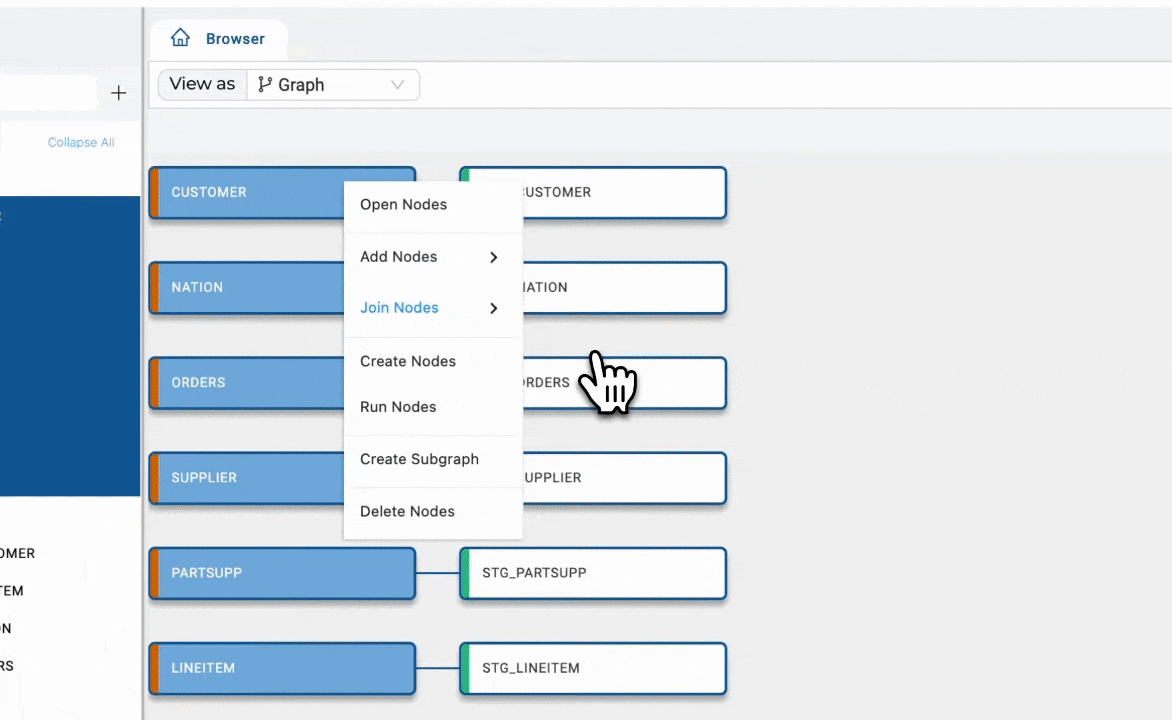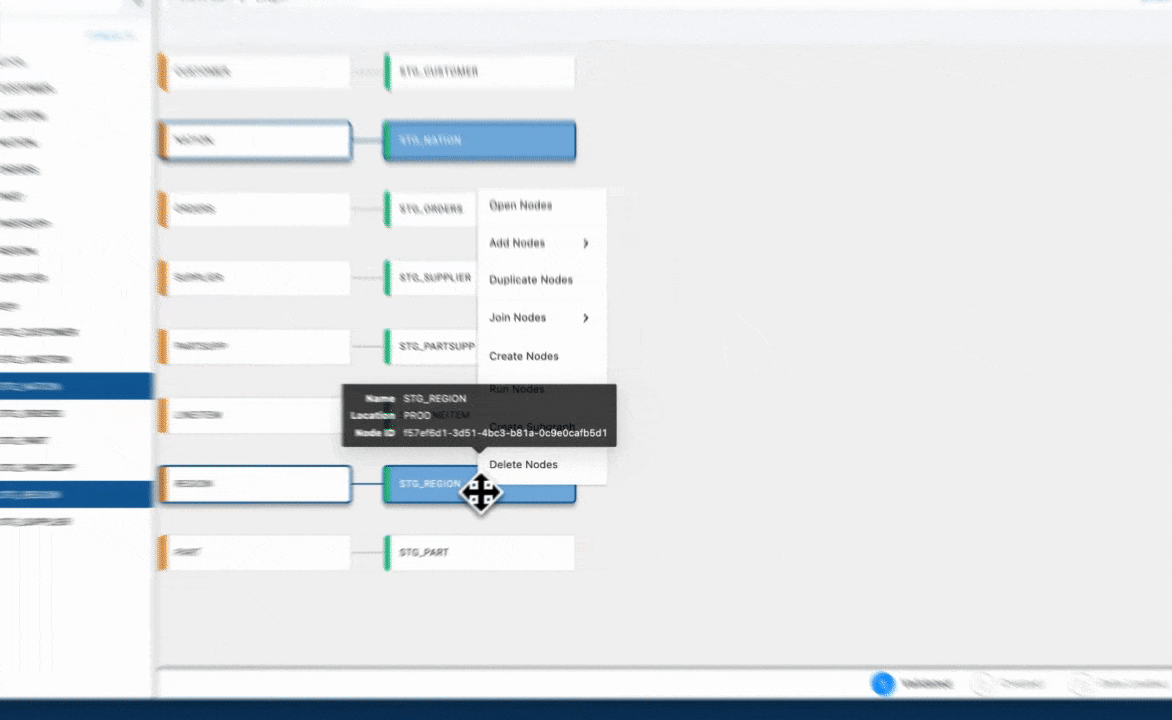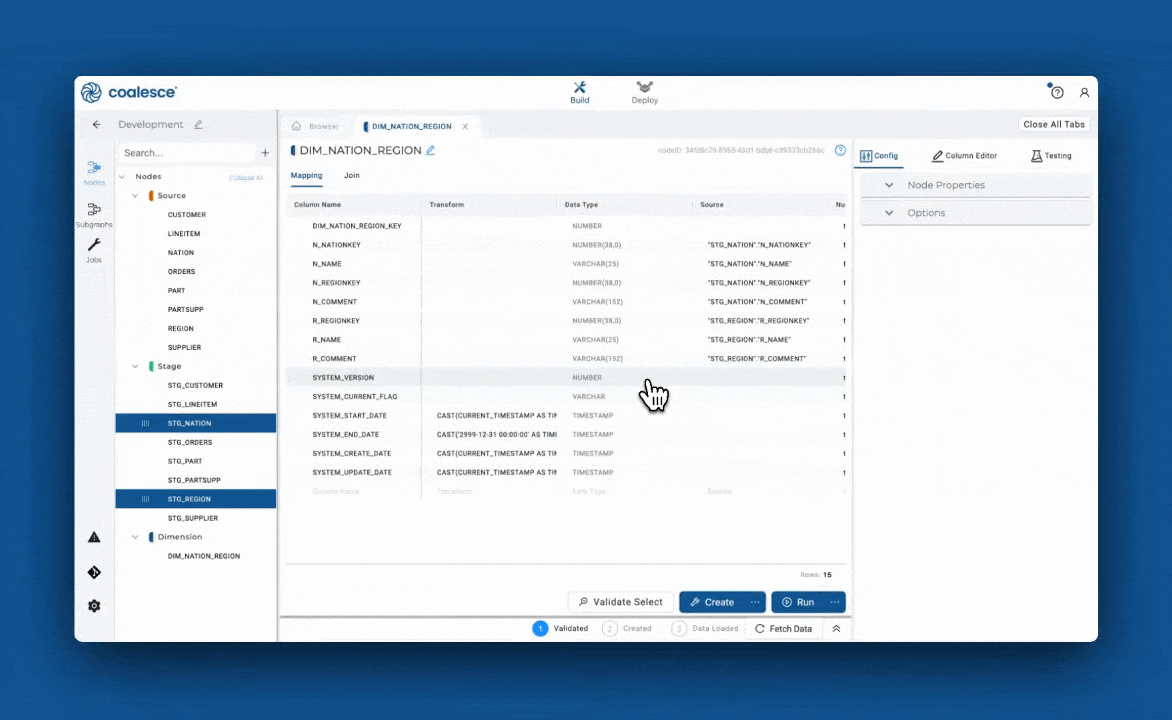
Visualizing and validating data flow
Coalesce goes beyond surface-level development. Its column-aware architecture provides granular visibility into the lineage and impact of every transformation. Teams can trace how each column flows through a pipeline, making governance, auditing, and impact analysis seamless. The platform validates dependencies before deployment, much like a compiler, helping catch errors early and ensuring trust in the output.

By treating each transformation as a function and pipelines as programs, Coalesce embeds software engineering best practices into the heart of data workflows.
Parameterization: Dynamic logic at scale
Customizing pipelines without duplicating logic
Coalesce enables dynamic and scalable logic through the use of parameterization. Parameters in Coalesce act like arguments in a function, allowing developers to define them once and use them throughout the pipeline. This design supports environment configurations, reusable transformation patterns, and runtime logic switching—without rewriting SQL.
Support for deploying to multiple environments
Instead of duplicating pipelines for different teams or regions, Coalesce allows for the definition of dynamic parameters that adapt logic based on deployment context. This supports workflows that can flex across use cases, from production to staging.
For example, a single pipeline can be configured to process different countries’ data simply by passing a country code as a parameter—such as “EMEA” or “LATAM”. The underlying SQL logic stays exactly the same, but the filter conditions and transformations adjust automatically at runtime. This approach not only avoids duplicating pipelines for each country or business unit, but also simplifies testing, debugging, and governance by maintaining a single source of truth.
Environment-specific configuration
| Environment | Parameter | Pipeline Output |
| Development | region = ‘EMEA’ | Filters data to EMEA region only |
| Staging | region = ‘LATAM’ | Filters data to LATAM region only |
| Production | region = ‘GLOBAL’ | Includes all regional data |
With this approach, teams can manage fewer pipelines and iterate more quickly while ensuring configuration consistency.
Developer tooling: Power and precision for engineers
Automation, version control, and reusability
Coalesce supports an array of developer-focused features designed to integrate with modern engineering workflows. Through its CLI, engineers can schedule pipeline runs, automate deployments, and incorporate Coalesce into larger orchestration systems. Every Coalesce project is backed by Git-style version control, enabling branching, committing, and merging..
Advanced users can define their own standards or templates, called User-Defined Nodes (UDNs), using YAML, SQL, and Jinja. These UDNs encapsulate complex transformation logic into repeatable components. Instead of copying and pasting SQL across different models, developers can invoke a UDN, customize its parameters, and maintain a single source of truth.
These tools align Coalesce with software engineering best practices. Pipelines become modular and testable. Code is versioned and reviewable. Deployments are automated and predictable. Engineers retain full control, while the platform abstracts away redundant work.
Real-world applications: Efficiency and scale in practice
Transforming data delivery across industries
The benefits of Coalesce are not just theoretical. Organizations using the data engineering platform have reported substantial improvements in productivity, cost savings, and collaboration.
Group 1001, an insurance provider, uses Coalesce to transform their data delivery timelines. What once took three months was accomplished in two days, thanks to reusable templates, automated lineage tracking, and modular pipeline design. The team of just five engineers migrated four terabytes of data in less than a year, illustrating the scale and speed enabled by Coalesce.
Similarly, digital media company TubeScience achieved a threefold increase in productivity and saved over $260,000 after adopting Coalesce. Their data team could collaborate more effectively with business stakeholders, thanks to the platform’s shared interface and reliable execution. Pipelines that previously took hours to debug and deploy now run smoothly and transparently.
These customer stories reflect a consistent outcome: faster delivery of trusted data with fewer resources and lower risk.
Conclusion: Coalesce sets a new standard
The future of data engineering is modular and governed
Coalesce isn’t just a visual data tool. It’s a robust data engineering platform that empowers data teams to build faster, maintain better, and scale smarter. By combining low-code development with developer-optimized tooling, Coalesce bridges the gap between accessibility and rigor. Teams no longer have to choose between agility and control. Coalesce delivers both.
Whether you’re building your first pipeline or scaling to thousands of tables, Coalesce offers a framework that supports automation, modularity, and governance. It transforms pipeline creation from an ad-hoc task into a disciplined engineering practice. With built-in lineage, reusable templates, version control, and dynamic parameterization, Coalesce ensures your data workflows are not only fast, but future-proof.
To see how Coalesce can accelerate your data projects, explore a live demo or start a free trial today. The future of data engineering isn’t just visual—it’s modular, governed, and built like software. And Coalesce is leading the way.